本文最后更新于 2024年1月4日 早上
说起AI绘画就不得不谈stable diffusion webui,但生成图片上下限都很夸张,参数巨多,使用繁琐。而本文是找一些简单模型来部署使用,即只是给出一些简单提示词,也能输出正常图片。将会部署成api服务,然后使用streamlit编写使用前端。
目前推荐使用sdxl-turbo,语言模型转化提示词后输入
1 中文StableDiffusion-通用领域
1.1 说明
该模型在魔塔社区看到的,为数不多支持中文提示词的模型。模型采用的是Stable Diffusion 2.1模型框架,将原始英文领域的OpenCLIP-ViT/H文本编码器替换为中文CLIP文本编码器chinese-clip-vit-huge-patch14,并使用大规模中文图文pair数据进行训练。训练过程中,固定中文CLIP文本编码器,利用原始Stable Diffusion 2.1 权重对UNet网络参数进行初始化、利用64卡A100共训练35W steps。
在作为一个普通用户,也即没有绘图提示词相关知识的使用者时,出图效果不怎了理想,各种奇形怪状,仍然需要不断优化提示词来修复,该模型的优势在能直接输出中文,其他方面不明显。
1.2 模型下载
代码中如果不指定模型地址,则会自动去下载,所以可以跳过此节。
- 模型名称:multi-modal_chinese_stable_diffusion_v1.0
- 原文链接:modelscope
- 模型大小:4.74G
- 下载
1
2
| from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('damo/multi-modal_chinese_stable_diffusion_v1.0', cache_dir='./models')
|
1.3 运行环境
1.3.1 anconda
至于anconda前面文章写过多次,这里不赘述了。
1
2
| conda create -n modelscope python=3.8
conda activate modelscope
|
安装pytorch,根据自己环境选择,这里使用CUDA 11.8
1
| conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
|
modelscope环境依赖
1
2
| pip install modelscope
pip install 'diffusers<0.21.0'
|
其他依赖
1
2
3
4
5
6
7
| fastapi
uvicorn
matplotlib
opencv_python
Pillow
PyYAML
openai==1.6.1
|
1.3.2 docker
可以使用下列dockerfile作为绘图服务的运行环境,api.py作为入口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
FROM registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu22.04-cuda11.8.0-py310-torch2.1.0-tf2.14.0-1.10.0
WORKDIR /app
RUN pip install 'diffusers<0.21.0' fastapi uvicorn matplotlib opencv_python Pillow PyYAML
EXPOSE 20010
CMD ["python", "api.py"]
|
生成镜像(gpu)
1
| docker build -t draw-api .
|
启动容器
1
| docker run -d -p 20010:20010 -v 你代码地址:/app --gpus all --name draw-api draw-api
|
1.4 代码
1.4.1 模型推理
此部分是是加载模型然后进行推理,封装成了一个类。代码中的加载MMCSD.yaml配置文件可以去掉,其实就只用了model_dir、image_save_dir、default_negative_prompt三个参数,模型保存地址如果没有则也会自动下载使用默认地址,而图片保存地址也只是在需要每次生成图片后保存到本地才用,最后的是默认的反向提示词,可以通过接口传入,只是懒得填可以用用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
| import cv2
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import datetime
import os
import torch
import yaml
import sys
from PIL import Image
import base64
import io
class MultiModalChineseStableDiffusion:
def __init__(self) -> None:
self.task = Tasks.text_to_image_synthesis
try:
config_path = os.path.join(os.path.dirname(os.path.realpath(sys.argv[0])),'config/MMCSD.yaml')
except:
config_path = "../config/MMCSD.yaml"
print(config_path)
self.config = yaml.load(open(config_path, encoding='utf-8'), Loader=yaml.FullLoader)
self.model_id = self.config["model_dir"]
self.image_save_dir = self.config["image_save_dir"]
self.default_negative_prompt = self.config["default_negative_prompt"]
if(self.model_id == ''):
self.model_id = 'damo/multi-modal_chinese_stable_diffusion_v1.0'
self.pipe = pipeline(task=self.task, model=self.model_id,torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32)
def run(self,text,steps=50,scale=7.5,negative_prompt="",save=False):
'''
text: 提示词
steps: 推理步数
scale: 调整负面提示词对其的影响
negative_prompt: 负面提示词
save: 是否保存图片
return: base64_img,save_path
'''
if negative_prompt == "":
negative_prompt = self.default_negative_prompt
output = self.pipe({'text': text, 'num_inference_steps': steps, 'guidance_scale': scale, 'negative_prompt':negative_prompt})
img = output['output_imgs'][0]
img = Image.fromarray(img[:,:,::-1])
buffer = io.BytesIO()
img.save(buffer, format='PNG')
base64_img = base64.b64encode(buffer.getvalue()).decode('utf-8')
if save == True:
current_time = datetime.datetime.now()
time_string = current_time.strftime("%Y-%m-%d_%H-%M-%S")
file_name = f"{time_string}.png"
save_path = os.path.join(self.image_save_dir,file_name)
cv2.imwrite(save_path, output['output_imgs'][0])
return base64_img,save_path
else:
return base64_img,None
if __name__ == '__main__':
client = MultiModalChineseStableDiffusion()
import matplotlib.pyplot as plt
base64_img,local_img = client.run("柴犬")
image_bytes = base64.b64decode(base64_img)
image = Image.open(io.BytesIO(image_bytes))
plt.imshow(image)
plt.axis('off')
plt.show()
|
1.4.2 API接口
这里使用fastapi搭建的接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| import json
import datetime
from channel.MultiModalChineseStableDiffusion import MultiModalChineseStableDiffusion
from fastapi import FastAPI,Request
app = FastAPI()
MMCNSD = MultiModalChineseStableDiffusion()
@app.post("/draw/channel_1")
async def draw(request: Request):
request_body = await request.body()
request_body = json.loads(request_body)
text = request_body.get('text')
steps = request_body.get('steps')
scale = request_body.get('scale')
negative_prompt = request_body.get('negative_prompt')
base64_img,save_path = MMCNSD.run(text=text,scale=scale,steps=steps,negative_prompt=negative_prompt)
return {
"text":text,
"steps":steps,
"scale":scale,
"negative_prompt":negative_prompt,
"base64_img":base64_img,
"time":datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
}
if __name__ == '__main__':
import uvicorn
uvicorn.run(app, host='0.0.0.0', port=20010, workers=1,log_level="info")
|
1.5 接口
请求:POST /draw/channel_1
参数:
| 参数名 |
类型 |
是否必选 |
示例值 |
描述 |
| text |
string |
是 |
“狗” |
要绘制的文本 |
| steps |
int |
是 |
50 |
绘制的步数 |
| scale |
float |
是 |
7.5 |
绘制的缩放比例 |
| negative_prompt |
string |
否 |
“” |
负面提示,可选参数 |
请求示例
1
2
3
4
5
6
7
8
9
10
| POST /draw/channel_1 HTTP/1.1
Host: localhost:1234
Content-Type: application/json
{
"text": "狗",
"steps": 50,
"scale": 7.5,
"negative_prompt": ""
}
|
返回参数
| 参数名 |
类型 |
示例值 |
描述 |
| text |
string |
“狗” |
绘制的文本 |
| steps |
int |
50 |
绘制的步数 |
| scale |
float |
7.5 |
绘制的缩放比例 |
| negative_prompt |
string |
“” |
负面提示 |
| base64_img |
string |
“iVBORw0KGgoAAAANSUhE…” |
绘制结果的 Base64 编码的图片字符串 |
| time |
string |
“2023-12-25 14:38:09” |
绘制完成的时间,格式为 “%Y-%m-%d %H:%M:%S” |
返回示例
1
2
3
4
5
6
7
8
9
10
11
| HTTP/1.1 200 OK
Content-Type: application/json
{
"text": "狗",
"steps": 50,
"scale": 7.5,
"negative_prompt": "",
"base64_img": "iVBORw0KGgoAAAANSUhE...",
"time": "2023-12-25 14:38:09"
}
|
1.6 演示前端
这部分使用streamlit实现,需要安装pip install streamlit
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| import streamlit as st
import requests
def drawing_page():
st.title("Drawing")
st.caption("文生图测试页面")
url = st.text_input("url", value="http://localhost:20010/draw/channel_1", key="base_url")
step = st.number_input("steps", value=50, key="steps")
scale = st.slider('scale', 0.0, 10.0, 7.5, key='scale')
negative_prompt = st.text_input("negative_prompt", value="", key="negative_prompt")
if prompt := st.chat_input("prompt"):
st.chat_message("user").write(prompt)
with st.chat_message('assistant'):
with st.spinner('Thinking...'):
try:
response = requests.post(
url,
json={
"text": prompt,
"steps": step,
"scale": scale,
"negative_prompt": negative_prompt
})
response = response.json()
base64_img = response["base64_img"]
image_tag = f'<img src="data:image/png;base64,{base64_img}" alt="base64 image">'
st.markdown(image_tag, unsafe_allow_html=True)
except Exception as e:
st.error(e)
st.stop()
if __name__ == "__main__":
drawing_page()
|
启动:
1
| streamlit run web.py --server.port 1111
|
浏览器打开http://localhost:1111/即可
1.7 效果
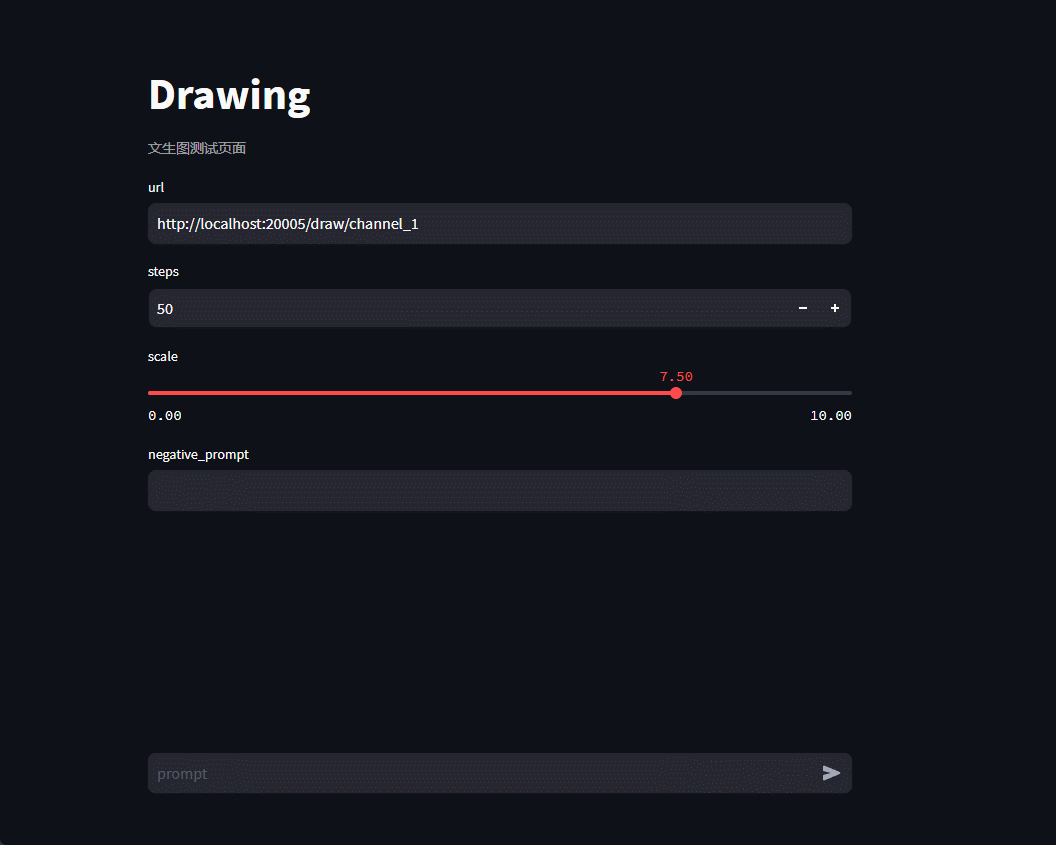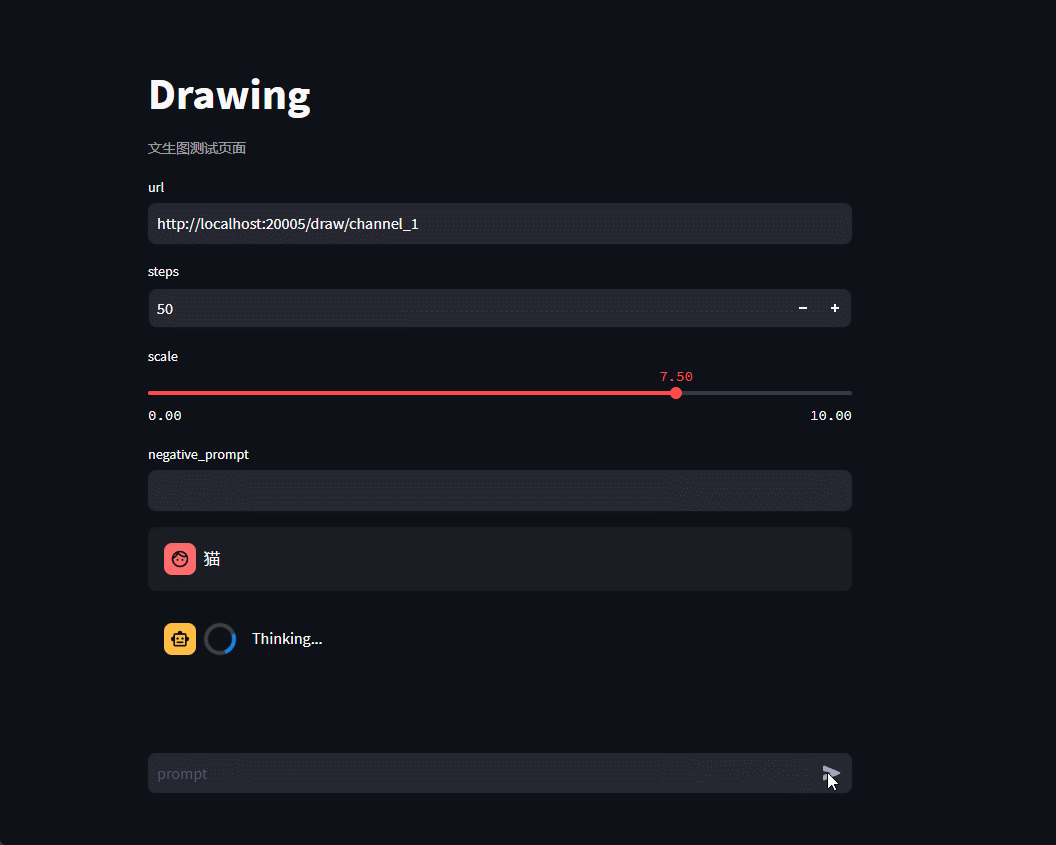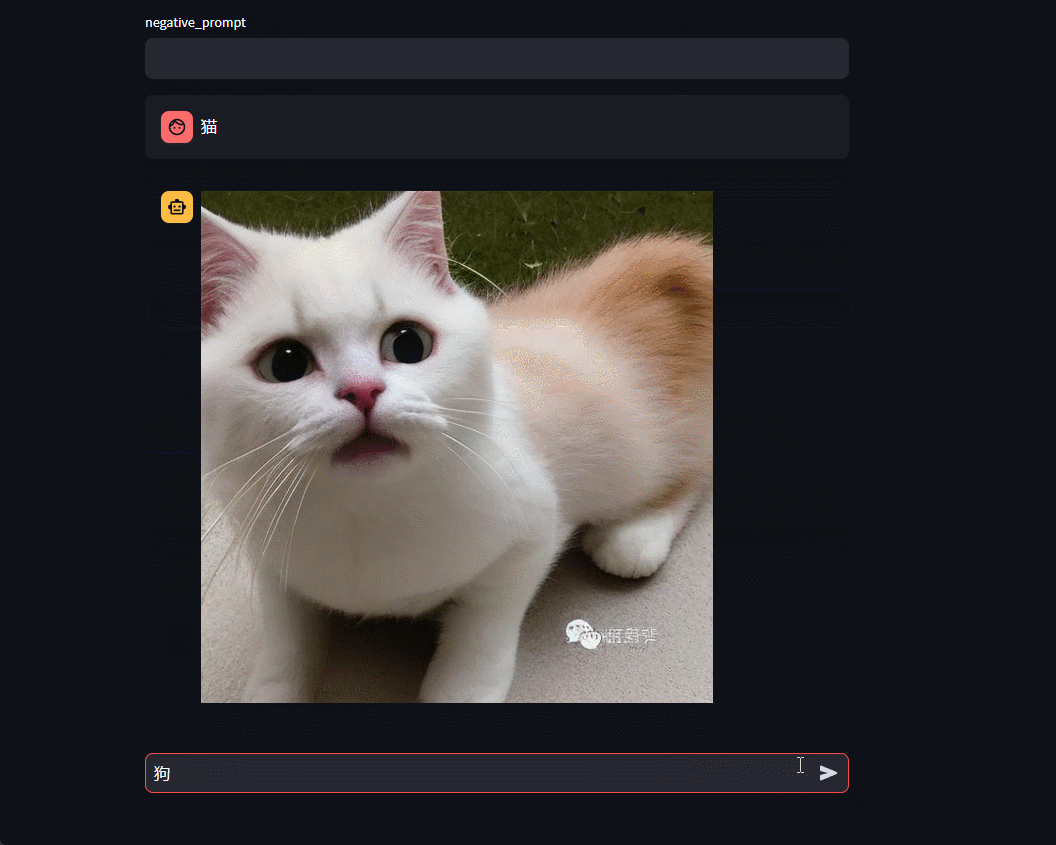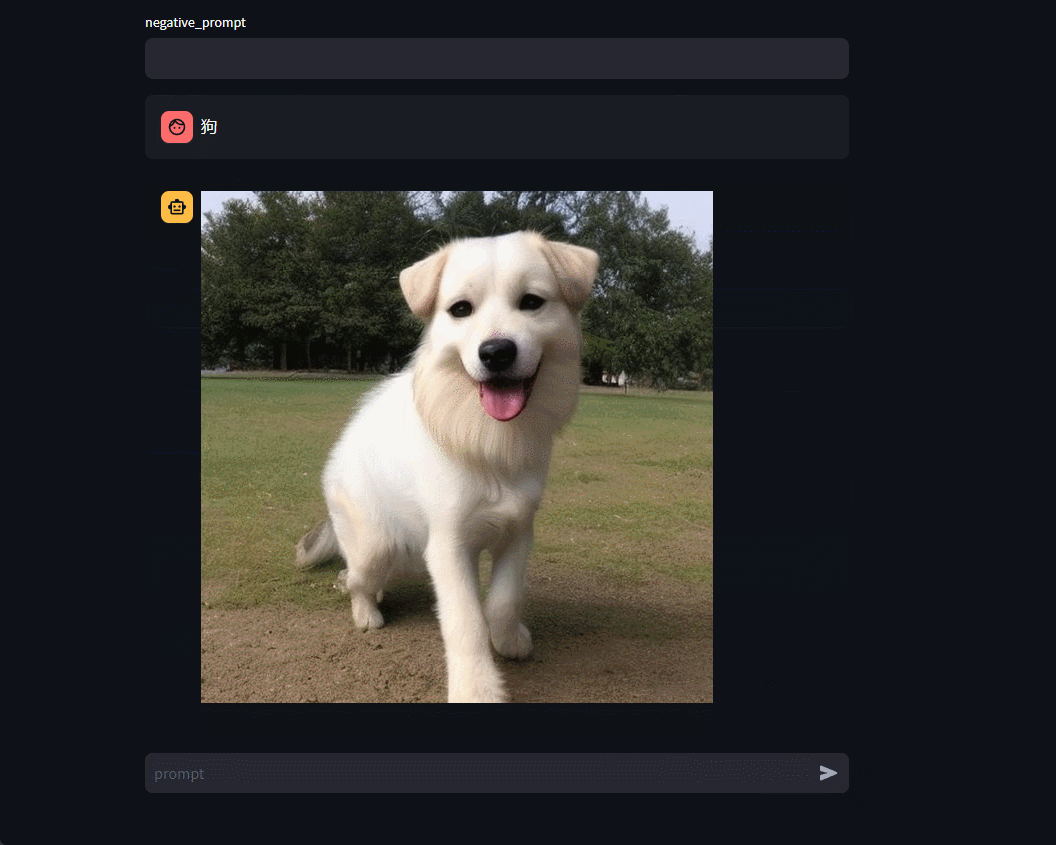
2 SDXL-Turbo
2.1 说明
SDXL-Turbo 是 SDXL 1.0 的精炼版本,仅通过1~4轮就能输出高质量图片。和母体一样,也是只支持英文,生成的图像具有固定分辨率(512x512 像素),对人或者认为面庞生成情况不理想。
就目前使用来看,该模型输出的图片还是挺不错的,没有出现各种诡异图像,文本和图像关联性也较强,最关键是你只需要填入提示词就行,其他参数没必要去动,极大方便了使用门槛。如果英文不好,那么可以和我一样使用对话模型去改提示词。
2.2 环境
模型运行后需要9G多显存,因为共享内存,所以8G显卡也能跑。
仍然需要pytorch
1
| conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
|
其他环境包:
1
2
3
4
5
6
7
8
| fastapi
uvicorn
diffusers
transformers
accelerate
PyYAML
streamlit
openai==1.6.1
|
2.3 代码
2.3.1 模型推理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
| from diffusers import AutoPipelineForText2Image
import torch
import os,sys
import yaml
import datetime
import base64
import io
from typing import Union
class SDXL:
def __init__(self, device="cuda",image_save_dir = "./temp"):
try:
config_path = os.path.join(os.path.dirname(os.path.realpath(sys.argv[0])),'config/SDXL.yaml')
except:
config_path = "../config/MMCSD.yaml"
if os.path.exists(config_path):
self.config = yaml.load(open(config_path, encoding='utf-8'), Loader=yaml.FullLoader)
self.model_name = self.config["model_dir"]
self.image_save_dir = self.config["image_save_dir"]
else:
print("{} 为找到文件,使用默认参数".format(config_path))
self.model_name = "stabilityai/sdxl-turbo"
self.image_save_dir = image_save_dir
self.pipe = AutoPipelineForText2Image.from_pretrained(self.model_name, torch_dtype=torch.float16, variant="fp16")
self.pipe.to(device)
def run(self, prompt,seed = 0, num_inference_steps=1, guidance_scale=0.0, save=True):
generator = torch.Generator()
generator.manual_seed(seed)
image = self.pipe(prompt=prompt,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
generator=generator
).images[0]
buffer = io.BytesIO()
image.save(buffer, format='PNG')
base64_img = base64.b64encode(buffer.getvalue()).decode('utf-8')
if save:
self.save_image(image)
return base64_img
def save_image(self,image,file_name=None,save_path=None):
if save_path == None:
save_path = self.image_save_dir
if file_name == None:
current_time = datetime.datetime.now()
time_string = current_time.strftime("%Y-%m-%d_%H-%M-%S")
file_name = f"{time_string}.png"
image.save(os.path.join(save_path,file_name))
def variations(self,image,prompt,steps=2,strength=0.5):
"""
图生图
传入图片url或者PIL.Image.Image,必须是方形
"""
from diffusers.utils import load_image
init_image = load_image(image).resize((512, 512))
image = self.pipe(prompt,
image=init_image,
num_inference_steps=steps,
strength=strength,
guidance_scale=0.0).images[0]
buffer = io.BytesIO()
image.save(buffer, format='PNG')
base64_img = base64.b64encode(buffer.getvalue()).decode('utf-8')
return base64_img
if __name__ == "__main__":
test = SDXL(image_save_dir="./")
base64_image=test.run("dog")
print(base64_image)
|
2.3.2 API接口
这里的接口仿照了openai的文生图接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| from pydantic import BaseModel
from typing import List, Optional
from fastapi import FastAPI
import time
import os,sys
import yaml
config_path = os.path.join(os.path.dirname(os.path.realpath(sys.argv[0])),'config/default.yaml')
config = yaml.load(open(config_path, encoding='utf-8'), Loader=yaml.FullLoader)
app = FastAPI()
class ImageData(BaseModel):
b64_json: str
revised_prompt: str
class ImageResponse(BaseModel):
created: int
data: List[ImageData]
class ImageRequest(BaseModel):
model: str = "sdxl-turbo"
prompt: str
size: str = "512x512"
response_format: str = "b64_json"
style :str = "natural "
n :int = 1
from channel.sdxl import SDXL
channel = SDXL()
@app.post("/v1/images/generations", response_model=ImageResponse)
async def generate_image(request: ImageRequest):
seed = config["sdxl_turbo"]["seed"]
steps = config["sdxl_turbo"]["steps"]
new_prompt = request.prompt
base64_img = channel.run(prompt=new_prompt,seed=seed,num_inference_steps=steps,save = False)
result = ImageData(b64_json=base64_img, revised_prompt=new_prompt)
return ImageResponse(created=int(time.time()), data=[result])
if __name__ == '__main__':
import uvicorn
uvicorn.run(app, host='0.0.0.0', port=20005, workers=1,log_level="info")
|
2.4 接口
2.5 演示前端
为了方便调试,很多东西写死,之后开源出来
3.6 效果
山重水复疑无路,柳暗花明又一村

一只可爱的柴犬正趴在地上睡觉

水墨画,山,水,树,亭子,冬天,白雪,禁止文字

水光潋滟晴方好,山色空蒙雨亦奇
