RVC变声探索
本文最后更新于 2026年4月17日 早上
本文是对变声框架Retrieval-based-Voice-Conversion-WebUI的使用笔记,包含训练、推理的流程和一些经验。
1 下载软件
这里推荐直接去这里下载RVC-beta.7z的压缩包,或者百度云,不然你就得和我一样执行下面两步。
克隆仓库
1 | |
下载模型huggingface:
* 页面根目录下的hubert_base.pt,下载到项目的assets\hubert目录下
* 页面中的pretrained、uvr5_weights 、pretrained_v2三个文件夹全都复制到项目的`assets\文件夹中去
2 配置环境
安装torch,这个就不谈了,根据troch官网安,我之前的文章好像也写过了好多次。
安装软件的相关依赖(N卡,其他型号去看仓库的readme吧,这里只记录我的流程)
1 | |
安装ffmpeg,ubuntu就直接下列命令安装,windows去下载个exe后添加到环境变量中
1 | |
rmvpe 人声音高提取算法所需文件
- 下载rmvpe.pt扔到项目根目录
- 下载rmvpe.onnx也扔到根目录
3 运行并推理(web UI)
在项目根目录执行
1 | |
推理界面:
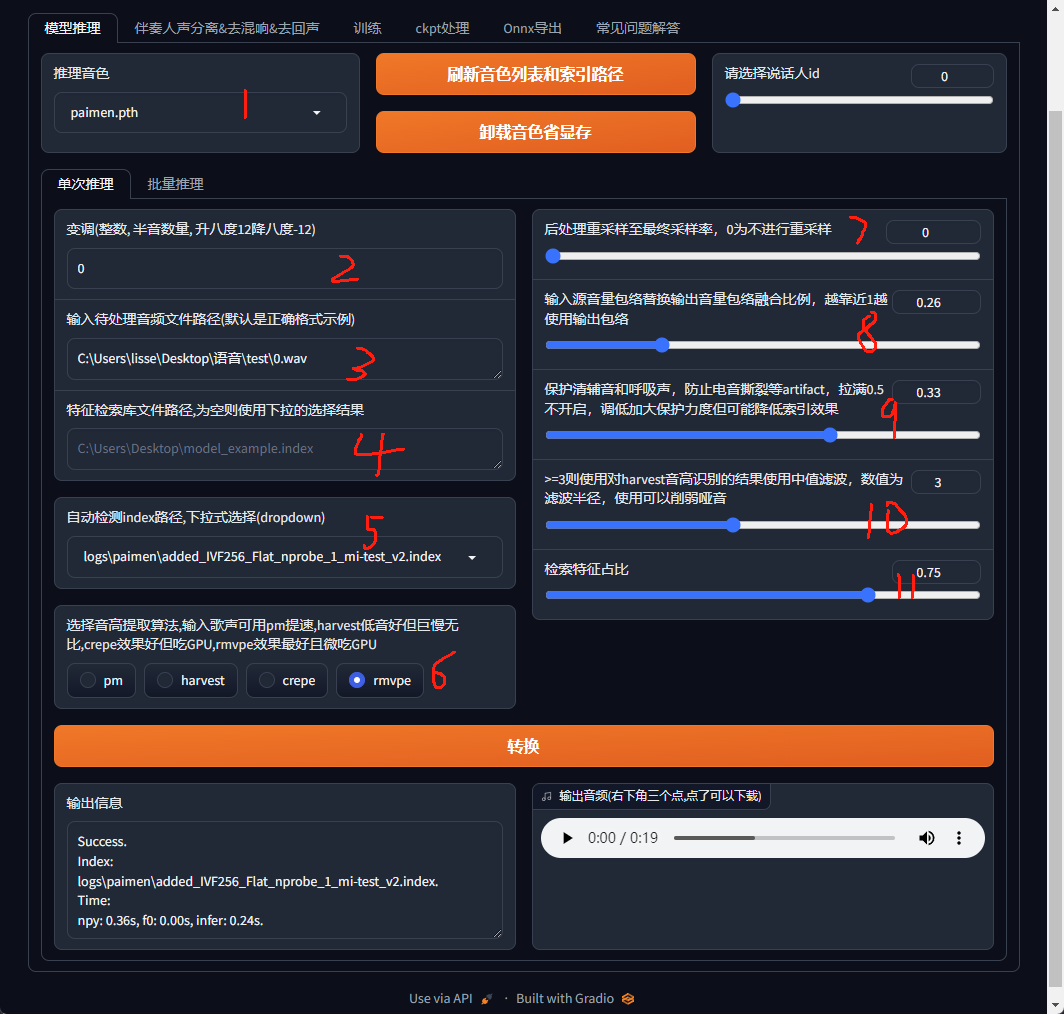
- 1 选择模型,也就是将输入音频转化为什么音色。对应文件夹
assets\weights。根据训练数据不同,转录唱歌的模型,转普通语音的模型是有区别,但是网上找的模型一般啥都不知道,只能自己试效果咯。 - 2 变调,如果输入音频文件的声调高于声音模型,则下调,反之则上调,这里就慢慢调,觉得那个数值更像就用哪个,没有什么固定标准。
- 3 选择输入音频,也就是要转化的音频。需要去掉背景音,否则输出会被背景音影响。可以使用子页面
伴奏人声分离或者这个web分离 - 4 特征检索库文件也就是那个index,有的模型提供了有的没有,可以通过这里手动填写地址。index文件不填也可以生成,但是会影语气音色等效果
- 5 自动检索实际上就是在logs文件夹中根据模型文件名查找对应名称的index文件,也可以搜索同名文件夹中的indx。所有由此可知,如果你找了个别人的模型,里面可能有两个文件一个
xx.pth,一个xx.index,前者扔到assets\weights,后者扔到logs文件夹中 - 6 直接默认的rmvpe
- 7 对音频进行重新采样以达到最终期望的采样率
- 8 这个参数控制了源音量包络和输出音量包络在融合过程中的权重比例,影响最终音量包络的形状和效果。通过调整这个参数,可以控制输出音量包络与源音量包络之间的平衡,达到所需的音量效果。
- 9 如其言,降低可以让声音不那么机械化,拉满则不开启这功能。
- 10 比如唱歌时的一些高音,变声后这里会哑掉,该参数就是解决这个问题的,当然也和模型本身有关。
- 11 越低时语气和口语越接近输入音频,越高越接近模型,前提是要给个index,变化得是语气和口音,对音色没有影响。
一般来讲,首先只需要点击刷新音色列表那个按钮,再选择音色模型,根据情况修改变调,就可以点转换了。
转录出来的声音语速语调都不会改变,改变的只是音色,所以如果想要模仿,那么输入的音频的说话方式也要跟着改变才行,你觉得输出的音频不像,很可能是这个原因,当然也可能是模型本身问题。
界面里面的参数返回可以修改infer-web.py,例如要修改总训练轮数,对着汉字搜索即可,找到maximum,就能修改最大值了。
4 训练模型
4.1 准备数据
这个不需要标注,只要把音频扔到一个文件夹即可。并且不需要手动分片,框架可以自动分片。
至少需要10分钟以上的音频,音频质量肯定越好越好,并且最好是干音,也就是去除掉伴奏、环境音、混响等,否则就用工具去处理,比如子页的伴奏人声分离&去混响&去回声的功能,或者Ultimate Vocal Remover等软件
现在去找处理好的数据比较难咯,毕竟这个涉及到版权问题。
Ultimate Vocal Remover的使用
首先下载模型,点击页面左下方的扳手,然后弹出选择第三项Download center(这里是需要梯子的)
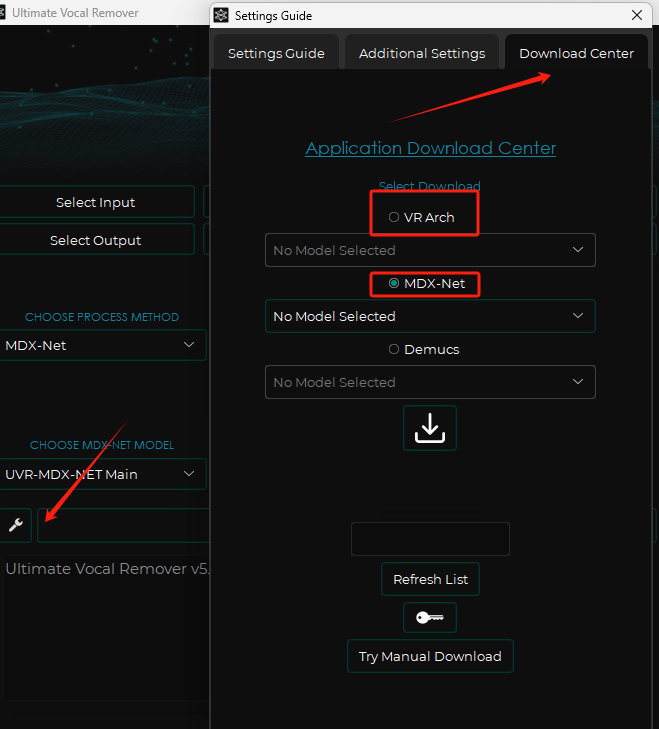
在MDX-NEX中下载模型:
- UVR-MDX-NET Main
- MDX23C-InstVoc HQ
在VR Arch中下载模型:
- 5_HP-haraoke-UVR
- UVR-DeEcho-DeReverb
- UVR-De-Echo-Aggressive
- UVR-De-Echo-Normal
第一次进行人声伴奏分离:
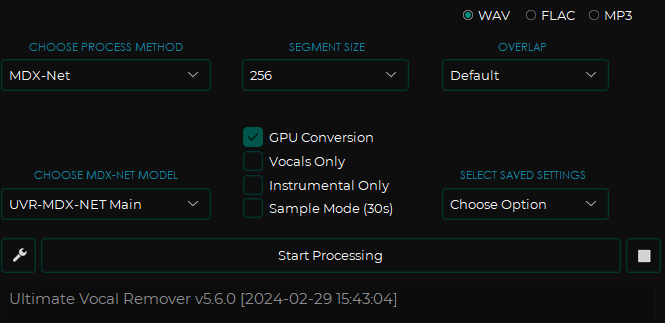
- CHOOSE PROCESSING MODE:选择模式
- VR Architecture: 使用幅度谱图进行声源分离。
- MDX-Net: 使用混合谱图网络进行声源分离。
- Demucs v3: 同样使用混合谱图网络进行声源分离。
- Ensemble Mode: 同样使用混合谱图网络进行声源分离。
- Audio Tools: 附加实用工具,以增加便利性。
- SEGMENT SIZE:理论越大质量越好,但更耗时。默认即可
- OVERLAP:也是数字越大质量越高,但是感觉听起来没啥区别,也默认吧
- CHOOSE MDX-NET MODEL:选择模型
- UVR-MDX-NET Main
- MDX23C-InstVoc HQ
第二次分离混合人声:
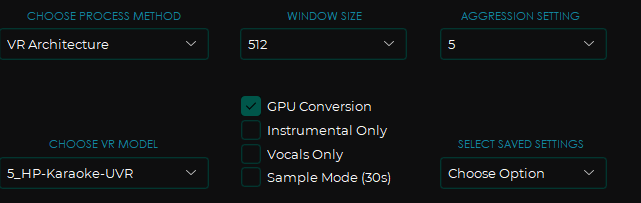
将上一次的输出音频作为输入
- WINDOWS SIZE:最小质量越高,继续默认
- AGGRESSION SETTING:和声的检测范围,目前也是默认值下输出的音频处理效果就不错,看之后处理不了再来试着调。
- CHOOSE VR MODEL:选择模型
- UVR-DeEcho-DeReverb:去混响降噪(激进)
- UVR-De-Echo-Aggressive:去混响降噪(平均)
- UVR-De-Echo-Normal:去混响降噪(温和)
- GPU Conversion :使用GPU推理,提高速度
- instrumental only : 只输出伴奏
- vocal is only :只输出人声
- sample mode(30s):当分离音频比较大时,使用它可以分离前30秒来查看效果
点击start Processing即可开始分离
4.2 训练
这里先说最简单的方式:
* 修改输入实验名的空,给模型取个名字吧
* 修改输入训练文件夹路径,就是你训练数据保存的文件夹
理论上其他啥都不动,直接点击一键训练就可以跑出来个模型了。接下来逐个说明下各个选项的意思。
step1

- 输入实验名:也就是模型的名字,当填写
assets\weights中已有的模型名字时,训练时会读取直接的记录,开始继续训练。 - 目标采样率:这个根据自己需求改就是了。
- 模型是否带音高指导:简而言之是转唱歌时使用,转普通语音时不用。如果使用了高音指导,但是转语音可能会发生气音、哑音等情况。
- 剩余两个没必要动了。
step2

- 1 训练音频的文件夹地址,如果再次训练时可以不用填写,因为实际训练的数据是处理后保存在logs文件夹中的音频。现在不支持多角色训练,所有说话人id也不用动。
- 2 选择gpu,我这里虽然有三张卡,但是只准备用第一张来训练,所有改成了0,默认是全选,说要一般不用改。
- 3 音高提取算法,仍然可以默认,我这样因为只要使用第一张GPU,所有将下面全改成0了
step3
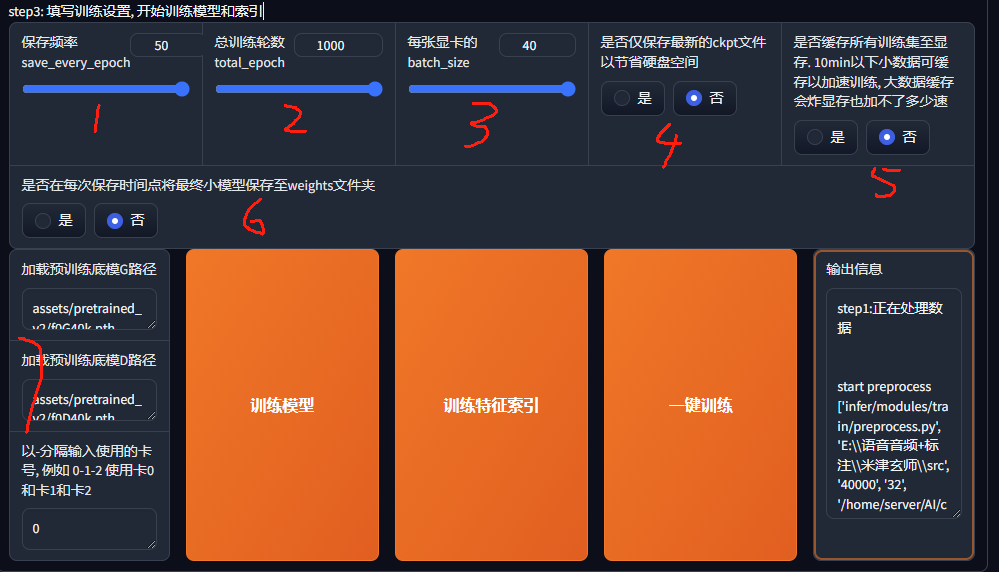
- 1 保存频率,也就是每训练多少轮保存一个模型,比如设置成50,总训练100轮,那么最终你将得到两个模型。
- 2 总训练轮数,时间足够,那最好设置个大值,然后配合上面的参数,测试到底哪个轮数的模型效果最好即可。
- 3 这个参数你可以理解一步跨越多长,当然跨的越长就走得越快,如果设置成最大值40,那么会消耗19G左右的显存,但是有个问题是可能会发生在最优解左右激荡,始终下不去的情况。
- 4 是否仅保存最新的ckpt文件,如果设置成否,那么会根据之前设置的
保存频率得到多个模型,不然就只得到最终的一个模型。 - 5 默认选择否。
- 6 这里就是将中途保存的模型也移动到weights文件夹,你就可以通过推理页面之间选择它了,否则只会移动最终的模型
- 7 默认即可
点击一键训练,训练后会在终端看到如下打印:

继续训练,只需要填写之前的项目名称,然后训练轮数大于之前的即可,如果更换设备训练,则需要将logs对应项目名文件夹中的G_XX.pth和D_XX.pth一起转移
5 变声客户端
可以直接查看别人的说明文档照着弄,或者看下面的流程。
这里需要安装对应环境
1 | |
然后安装虚拟声卡软件,安装之后在声音设置将voiceMeeter Output设置为默认设备。
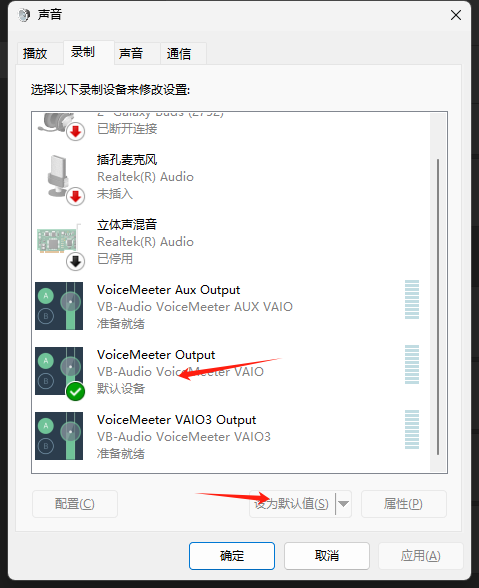
启动变声软件
1 | |
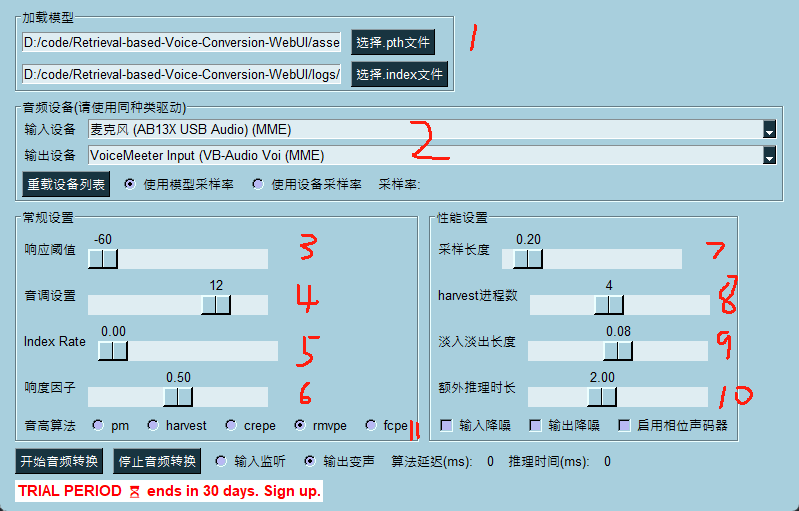
- 1 模型选择,直接指定.pth和.index文件
- 2 将输入设备选择成你准备使用的麦克风,输出设备则必须设置为如图这个,也就是之前在声音配置那里设置的默认设备。
- 3 接收声音的阈值,默认最低,但是可能会有比较大的环境噪声。可以勾选软件中的降噪功能。
- 4 音调设置,男转女一般在10
12,在这附近左右调整,分别可以变粗或变细,女转男一般在-12-10左右。 - 5 index rate,就是之前的特征索引占比,越低越接近底模,越高越接近模型,前提是要给个index,变化得是语气和口音。
- 6 响度因子,默认
- 7 采样长度,越低越好,但是太低会造成cpu暂用高,并且如果推理速度跟不上,会造成声音卡顿。
- 8 harvest进程数,当使用harvest时生效,不过用rmvpe就无视了。
- 9 淡入淡出长度,音频之间的间隔,间接影响了时长。
- 10 额外推理时长,1~3s,至少1秒,效果越长越好,调高了咬字识别更好。会影响CUDA占用
6 代码推理
**更新:我写了个推理工具,能清洁音频、音频变声和视频变声,github仓库voice-morph**,支持命令行和web界面使用。
如果需要在自己的程序中添加RVC,可以使用该作者的另一个仓库,这个仓库很多部分还没写,但是就用来推理是足够了。
和之前一样的环境,这个只是没有web界面而已,首先克隆仓库:
1 | |
然后将相关模型仍进去,地址随便,反正后面通过env配置。这里列举一下相关模型
- hubert_base.pt
- rmvpe.pt
- rmvpe.onnx
- 音色的推理模型,就是那个pth和index
- uvr5的相关模型
之后就是使用的示例:
- 在根目录创建个.env,填写上面模型仍的地址
1
2
3
4
5
6weight_root="D:\\code\\Retrieval-based-Voice-Conversion\\rvc\\assets\\weights"
index_root="D:\\code\\Retrieval-based-Voice-Conversion\\rvc\\assets\\weights"
rmvpe_root="D:\\code\\Retrieval-based-Voice-Conversion\\rvc\\assets"
weight_uvr5_root="D:\\code\Retrieval-based-Voice-Conversion\\rvc\\assets\\uvr5_weights"
hubert_path="D:\\code\\Retrieval-based-Voice-Conversion\\rvc\\assets\\hubert_base.pt"
save_uvr_path="D:\\code\\Retrieval-based-Voice-Conversion\\rvc\\result\\save_uvr" - 在根目录创建一个示例代码
test.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22from pathlib import Path
from dotenv import load_dotenv
from scipy.io import wavfile
from rvc.modules.vc.modules import VC
import os
def main():
vc = VC()
vc.get_vc("hutao.pth")
tgt_sr, audio_opt, times, _ = vc.vc_single(
sid=1,
input_audio_path=Path("E:\\audio_AI\\audio\\test\\2.wav"),
f0_up_key=12
)
wavfile.write("D:\\code\\Retrieval-based-Voice-Conversion\\rvc\\result\\out2.wav", tgt_sr, audio_opt)
if __name__ == "__main__":
load_dotenv()
a = os.getenv("weight_root")
print(a)
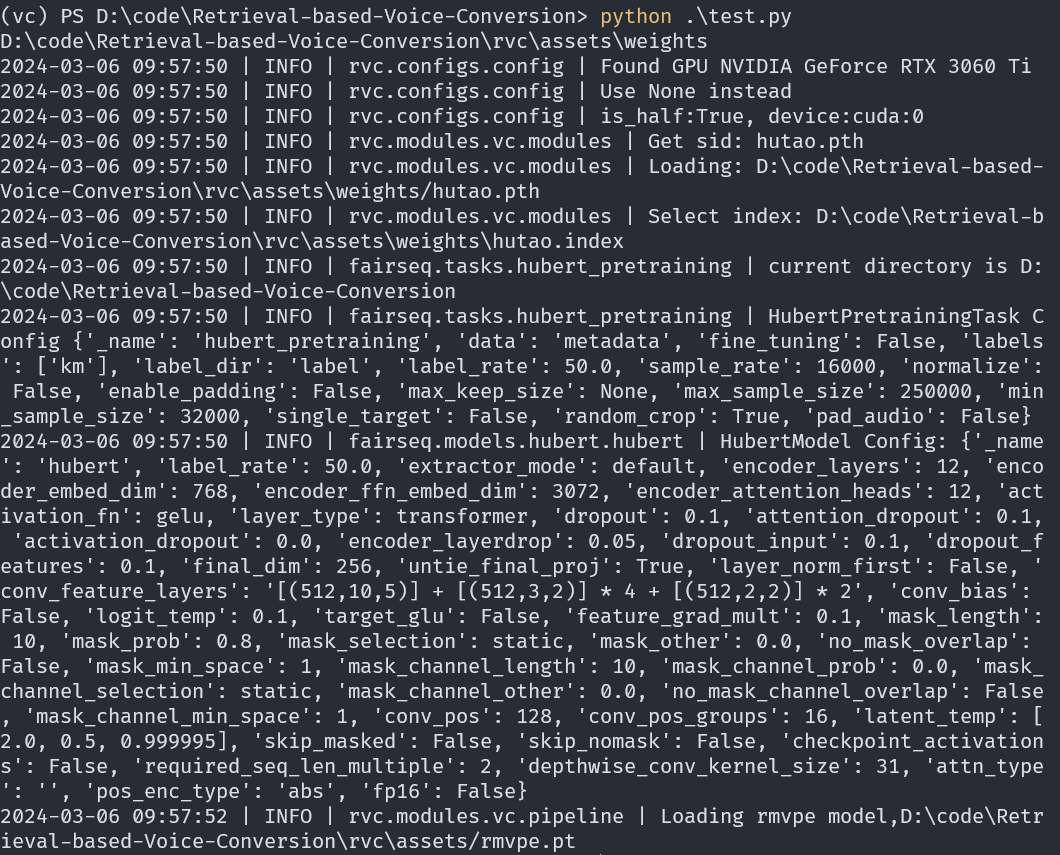
main() - 直接运行
其他
- 变声框架 Retrieval-based-Voice-Conversion-WebUI
- RVC作者的B站空间
- 一个共享模型的网站:voice-models.com
- 伴奏分离工具Ultimate Vocal Remover