stable diffusion webui (AI绘图)
本文最后更新于 2026年4月17日 早上
AI绘画,早前火的时候我本来想玩玩,但是公司里面研究这个旁人看来就觉得:这货在摸鱼,看黄图。家里电脑显卡又太垃圾,于是一直没碰。最近公司有需求,于是就合法探索,本文记录SD的部署和基本使用。
1 安装(ubuntu)
- conda虚拟环境,python=3.10,CUDA。这些之前有写过,这里就不重复了
- 安装torch(根据电脑的cuda版本)
1
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 - 克隆仓库
1
https://github.com/AUTOMATIC1111/stable-diffusion-webui.git - 安装依赖
1
2pip install -r requirements_versions.txt
pip install -r requirements.txt
2 运行
1 | |
运行时报错:
1 | |
需要在启动时添加参数
1 | |
如果需要一个公网域名可以编辑webui.py,修改share=True1
2
3
4
5app, local_url, share_url = shared.demo.launch(
#share=cmd_opts.share,
share=True,
server_name=server_name,
以下省略如果需要在局域网运行,则修改./modules/cmd_args.py,添加default=True1
parser.add_argument("--listen", action='store_true',default=True, help="launch gradio with 0.0.0.0 as server name, allowing to respond to network requests")如果就在本机使用,那么就啥都不修改,直接执行:1
2
3python launch.py
#换端口就加上--port 23234,或者和上面一样去修改cmd_args.py中的--port默认值
#需要密码就加上--gradio-auth username:password
- 运行的时候报错说找不到模型什么的,没啥关系,后面去下载就行了
3 使用
3.1 插件
如果安装报错: Error completing request
那么去修改./modules/shared.py
1 | |
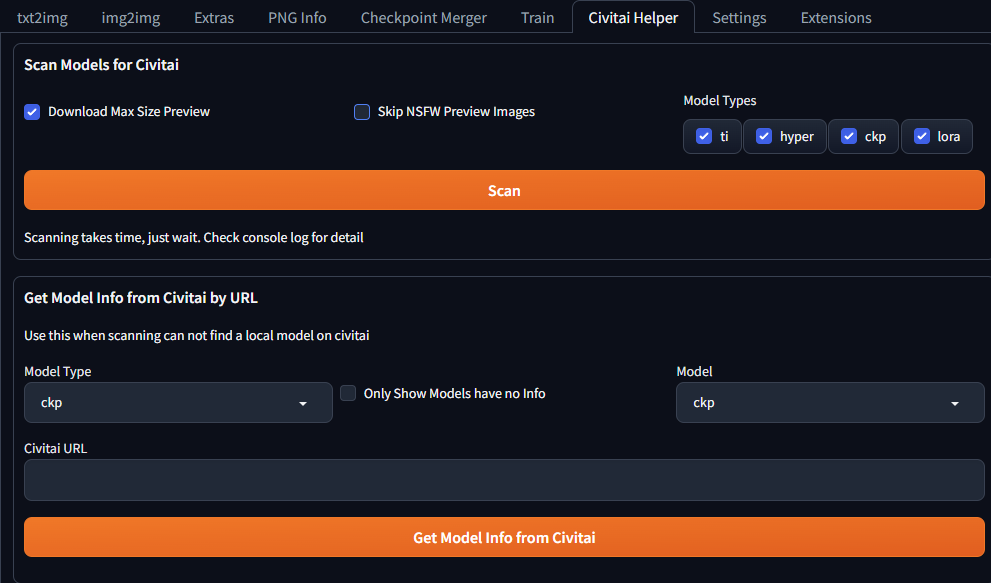
3.1.1 Civitai助手
该插件能够从Civitai下载、更新模型或者对已经下载的模型拉取消息,在web页面上安装
- Extensions -> install from URL
- 将
https://github.com/butaixianran/Stable-Diffusion-Webui-Civitai-Helper填入 - install
- 重启
- 之后在菜单栏会多出一个Civitai Helper
由于civitai需要梯子,所以自行参考v2rayA。
3.1.2 汉化
- Extensions -> install from URL
- 填入
https://github.com/VinsonLaro/stable-diffusion-webui-chinese - install
- 重启
- Settings -> 左侧选择User interface -> 打开第一个选项Localization -> 选择Chinese-English
3.1.3 提示词插件
也可以将插件扔到extensions目录中
进入extensions
下载插件
1
git clone https://github.com/n714/sd-webui-easy-prompt-selector-zh_CN.git重启
提示词仓库:https://github.com/n714/stable-diffusion-prompt-library-zh_CN, 用于替换插件中的tags
3.1.4 安装ControlNet和OpenPose模型
ControlNet插件,仍然是在Extensions中通过链接安装:
https://github.com/Mikubill/sd-webui-controlnet安装完成后在txt2Img可以看到多了个选项栏
之后下载openpose模型,control_v11p_sd15_openpose.pth,将其放到
stable-diffusion-webui\models\ControlNet文件夹中如果想自定义姿势可以安装open-pose-editor,地址:
1
https://github.com/ZhUyU1997/open-pose-editor.git
下图是使用controlnet的pose模型从图片中提取出骨架的预处理效果

3.2 模型
Stable Diffusion模型,初次运行时会发现有一个默认的模型v1-5-pruned-emaonly.safetensors,也就是基础模型,在web界面左上角可以选择。该模型被存放在models\Stable-diffusion目录中。基础模型确定了画面的整体风格,如卡通还是写实之类。
Lora模型,无线通信(误),微调模型,也即基于基础模型对其进行调整的模型,目在models\Lora。
VAE模型,大概是加滤镜的相关吧,还没用过,路径models\VAE,
主要就是通过他们的排列组合产出自己喜欢的图片。在下载模型的页面会有说明模型的类别,也可以通过这网站,帮助你知道它是啥,不过直接看大小也行,基础模型通常都是G单位,而lora通常就几十几百M。

这里先在civitai上下载个lora模型和基础模型。之后使用他们进行示例出图
3.3 参数
- CFG scale 提示词引导系数 值越大越符合给出的提示词描述,看网上图通常在7~12之间
- Sampling steps 迭代次数,通常越高的迭代次数会生成更好的图像质量,花费更多的时间,但过大后就没啥变化了。
- Batch count 同样参数生成轮数,每轮都会输出图,数量根据Batch size而定
- Batch size 每轮输出图数量
- Seed 随机数种子,主要就是通过它来产出不同的图片,也意味着相同的seed会输出相似图
- Clip skip 该参数需要在设置->用户界面中添加:
 先点应用再点重载,之后模型选择的右边就多了个clip skip的选项
先点应用再点重载,之后模型选择的右边就多了个clip skip的选项 - ENSD同样在设置里面,同样通过上面的方式搞个快捷设置,输入eta_noise_seed_delta。该值会对随机数种子进行偏移,当模仿图片时注意是否对其修改。
- Sampler 我就是根据模型的示例图选择对应的
- Width X Height 对于宽高的设置可以参考下使用的模型,模型会根据一类尺寸的图进行训练,使用相同尺寸图效果会更好
- 高清修复/Hires. fix,高清化算法选择ESRGAN_4x,重绘强度/Denoising strength是对放大后细节的修改程度,越大越偏离原图。放大倍率/Upscale by是对原图的放大倍数,例如512就变成了1024。
3.4 出图
点击菜单栏的txt2img,进行文本生成图片
点击生成按钮下方的书本图标,打开模型选择窗口
在checkpoints栏目点击模型revAnimated_v122
在lora栏目下点击add_detail,这时候提示词位置会自动填充,后面的数字是权重,表示增加或者减少细节,范围在-2~2
1
<lora:add_detail:1>然后写入提示词
1
<lora:add_detail:-0.5>, 1girl, loli, Slim, small breasts, elf , red eyes, white hair, very long hair, japanses clothes, grove, Morning禁止项,就是提升词下面那个,最开始没写,结果发现居然生成了漏点图,这模型不健康- -|
1
naked,bare随便改了改参数,点击生成,4090用了14秒出图。看着怪怪的,这里也就记录下流程,等之后试试其他模型。
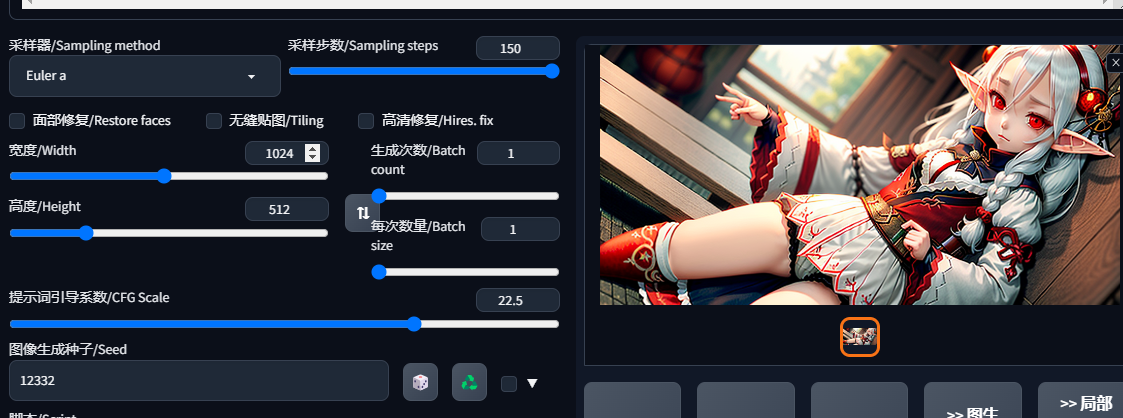
3.5 模仿出图
没啥经验的情况下,可以通过civitai上图片参数,进行模仿出图,例如此图,在图片右侧会显示:
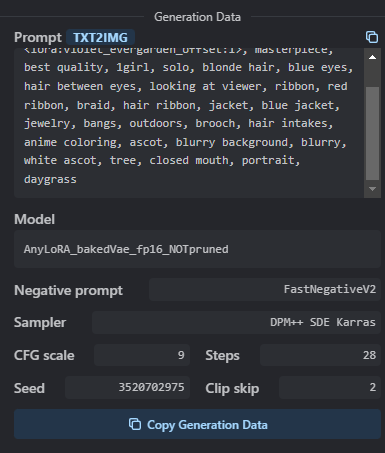
- 照着填入prompt的提示词
- 去下载AnyLoRA_bakedVae_fp16_NOTpruned模型,它是基础模型
- 下载lora模型violet_evergarden_offset
- 去下载FastNegativeV2反向提示词包,这里补充下,它的类型是embedding,也是扔到根目录的embeddings文件夹中。提示词包意思就是里面包含了很多提示词,方便用户直接引入,而不是每次都填写一大堆。
- 重启webui
- 取样器sampler选择DPM++ SDE karras
- 图片尺寸:512x704
- 反正就是参数照着填
最终输出图像(不加lora模型):

添加Lora模型后:

3.6 提示词
3.6.1 语法
- 英文
- TAG之间逗号分隔:
1gilr,long hair, blue eyes |符号可用于等比例混合两个提示词:1girl, long hair, blue|red eyes- 使用括号进行权重设置,范围0.1~100,默认为1,低于1则效果减弱:
(1girl:2), long hair, (blue eyes:0.5) - 单独使用
()和[]套入关键词分布表示增加1.1倍和减弱1.1倍
3.6.2 提示词
通常按照:画质->风格->主题->外表->情绪->姿势->背景->其他的顺序进行填写,但模型本身就定调了一些东西的时候,就可以省略一些。越重要的词就往前面放,相同含义的词放一起。关于具体的提示词,使用上文提到的提示词插件进行选择,还是挺方便的。
3.6.3 反向提示词
用于指定不要的特征,例如:naked,bare。我就发现这些模型,如果不填写经常输出些少儿不宜的图。以下是一个的反向提示词示例,当然也不需要写这么多。
1 | |