comfyui探索笔记
本文最后更新于 2026年4月17日 早上
早前玩过stable diffusion webui,那时候浅尝辄止,模型质量总是不如意,照着别人的生成图抄作业,稍微改改提示词就质量奇差。已经过去两年,又想玩玩,comfyui和dify一样工作流的方式,可玩性更高,本文是对其的探索。
安装
windows
在官网上有windows客户端,安装是非常简单,并且软件支持中文,所以这个步骤没啥卡点,唯一要注意的是安装位置,你之后可能会下载特别多模型,盘符容量要注意下。
现在软件中自带了ComfyUI Manager,可以直接在其中搜索自定义节点和模型进行下载,也是非常方便,记得之前导入别人的工作流,发现缺失一大堆,只能照着名字一个个去搜索下载,现在直接点击安装缺失自定义节点。
安装的时候如果出现下面列报错:
1 | |
找到在安装comfyUI时选择的目录中的配置文件,如comfy_file\user\default\ComfyUI-Manager修改安全等级
1 | |
可以额外选安装一个提示词插件,用来翻译和整理提示词还是挺方便,谁让我英语垃圾。后面流程也会涉及到这个自定义模块。
这些基础工作流都在comfyui的模板中能找到,所以下面的图都不是能直接拉进去的,直接去模板里面创建即可。
ubuntu
创建python环境:
1 | |
安装comfy-cli
1 | |
安装comfyui
1 | |
启动
1 | |
使用模板的时候,在自动弹出的模型安装界面,点击下载,居然是在我浏览器电脑上下载,要手动移动到comfy的文件夹中,怪不得旁边放个复制链接的按钮,是让我去服务器中手动下载吧。不过在manaager中倒是只能直接下载到对应目录。
文生图
这里列出一个最基础的文生图相关模块和工作流。
checkpoint加载器

这是最开始的模型加载模块,也就是加载主体的模型,会自动扫描comfyui\models\checkpoints文件夹中的safetensors文件。
这个节点有三个输出:
- 模型:如果需要串lora模型,则对接到相关的模块,如果不使用lora,则直接连接到
K采样器。 - CLIP:用于连接到提示词的模块
- VAE:如果不单独加载VAE模型,则该节点直接连接到
VAE解码的模块
提示词
这就是填写提示词的组件,一般需要两个,正向提示词和反向提示词。组件包含一个输入和一个输出。
输入节点clip,就是对接checkpoint加载器的输出,输出节点条件则需要连接到采样器组件中,如果是正向提示词,则连接到正面条件,反向提示词则就是负面条件。
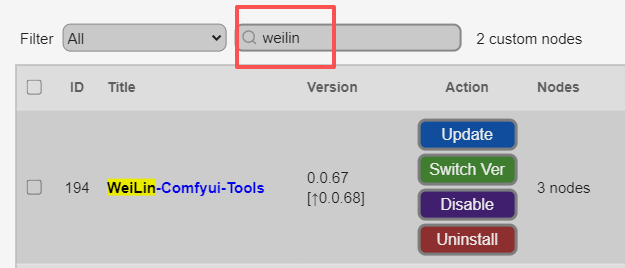
我现在是使用WeiLin-Comfyui-Tools来替代原有的提示词,我一般使用他的两个组件,一个是带lora的和一个只是提示词的,前者需要将checkpoint加载器的模型和clip节点均接入这个全能提示词编辑器,输出的模型和条件接入k采样器,单独提示词编辑器就和之前是一样的,下图就是替换后的样子。
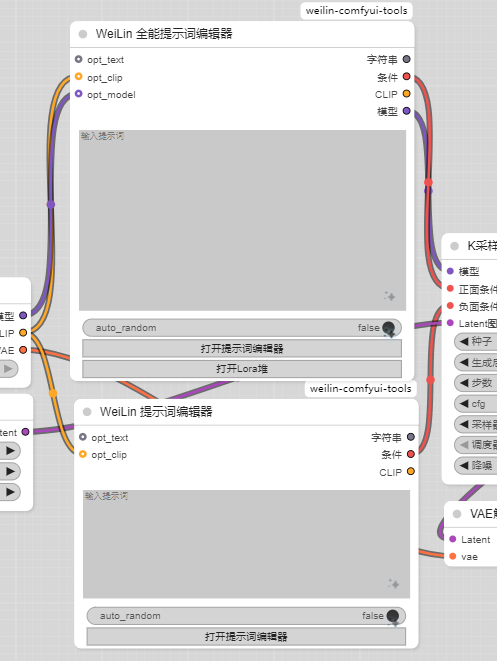
这个自定义组件使用方式就不谈了,全是中文,点击去看看就知道。
latent组件
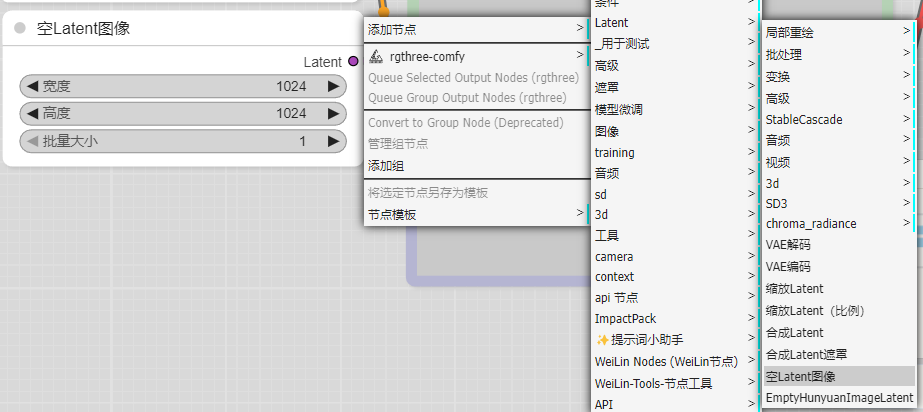
呃,就把这个组件当做一张空底稿吧,就三个参数,控制输出图的尺寸,和一次出几张图。输出就一个节点Latent,直接对接到K采样器中。
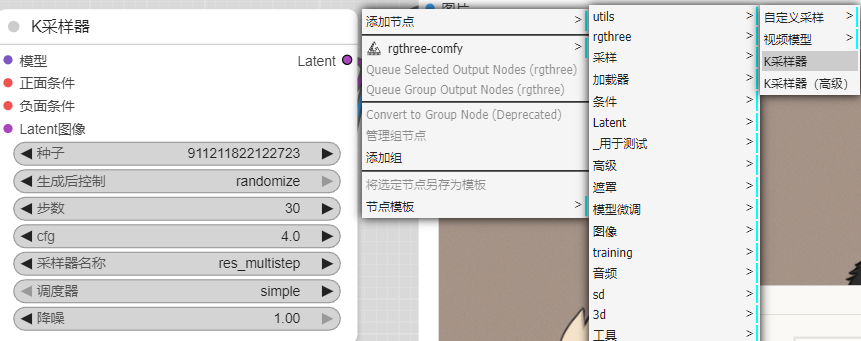
K采样器
这个就是生成图片的组件了,前面组件的参数均汇集于此。组件中的参数通常是跟着checkpoint模型来调,如果你想要复现别人的AI图,也可以跟着对方参数来设置。
VAE解码器
将latent图片还原为可视的真实图片。两个输入节点,一个是从K采样器而来的latent,一个是从checkpoint加载器或者vae加载器而来。最终就是输出图像,可以通过图像组件来显示。

效果
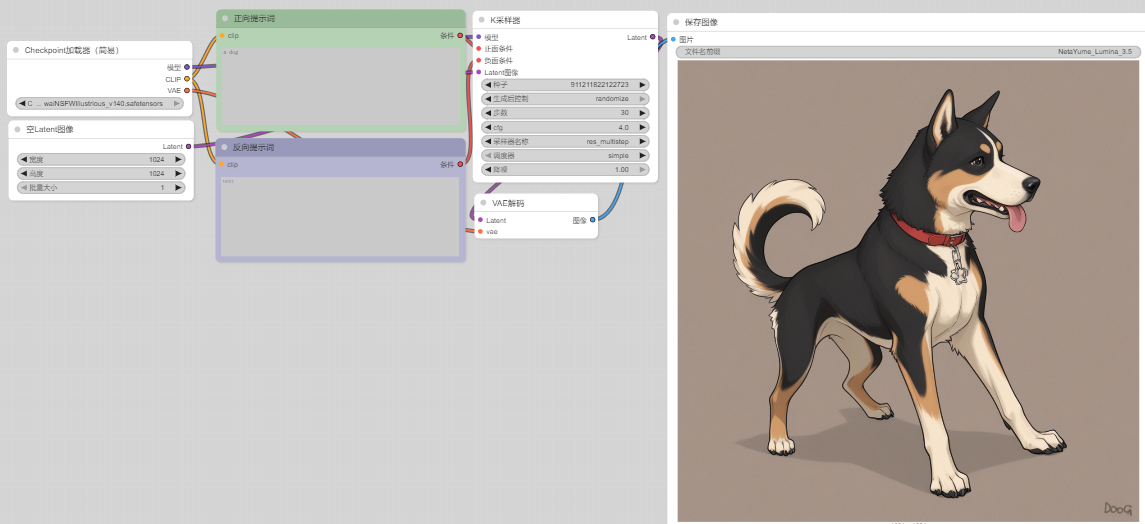
通过这些最基础的组件就能组合一个简单的文生图流程了
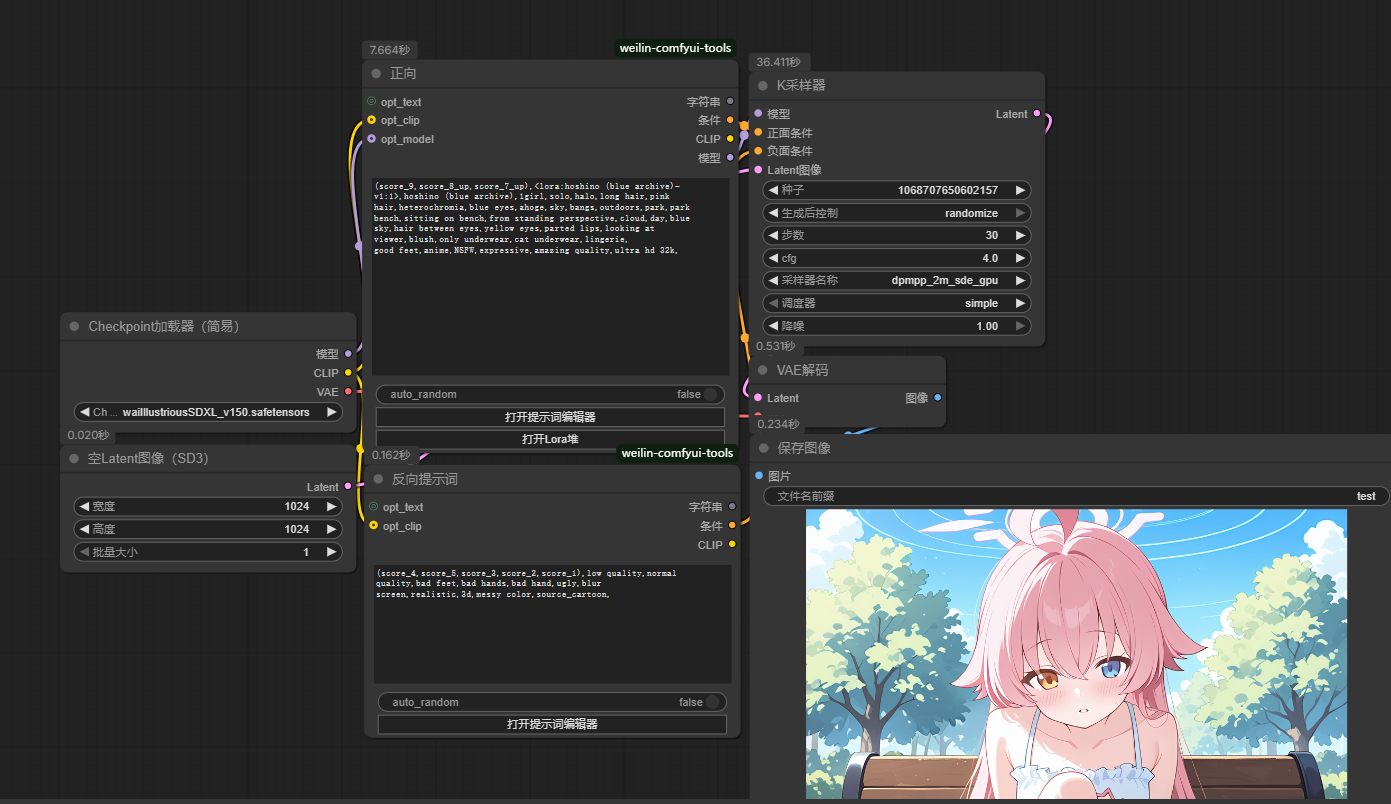
这是使用weilin提示词组件的流程,将lora模型加载融合,下列图就是加载星野lora的结果
模型
目前只对动画图片感兴趣,所以使用Illustrious类模型,在尝试了几类后感觉wai的模型效果比较好,而且常见角色也不需要额外lora。
模型页面也有一些参数说明
- 步骤:15-30
- CFG:5-7
- 采样器:Euler a
- 原始尺寸大于1024x1024
如果使用超分辨率的话:
- 放大倍数:1.5
- 高分辨率步骤:20
- 高分辨率放大器:R-ESRGAN 4x+ Anime6B
- 去噪强度:0.35~0.5
看v15就没有区分NSFW了,现在是有四个安全等级标签:general, sensitive, nsfw,explicit。
提示词不需要过多修饰质量
正向:
1 | |
负向
1 | |
lora训练
特别喜欢中秋星野的这套服饰,于是尝试训练。

首先去B站[下]了那个视频,但分辨率太低了,于是用Topaz Video提升到了2K,从中截图,由于也是只截取人身部分,所以看着特模糊,又用了开源的图片超分辨率工具upscayl,提升下。然后随便找个去背景的,把图片再刷一遍。
最后凑了20张:
之后是安装训练用工具kohya_ss,看这文档要去python的3.10或者3.11,之前环境就是3.10,就不用管,直接克隆仓库然后运行setup-3.10.bat,安装完后重新打开终端,再启动gui.bat
首先第一步,在顶部导航栏选择[lora],然后进入Training训练的子选项中。在下面找到Dataset Preparation数据准备的子标签。用它来生成一个目录结构。
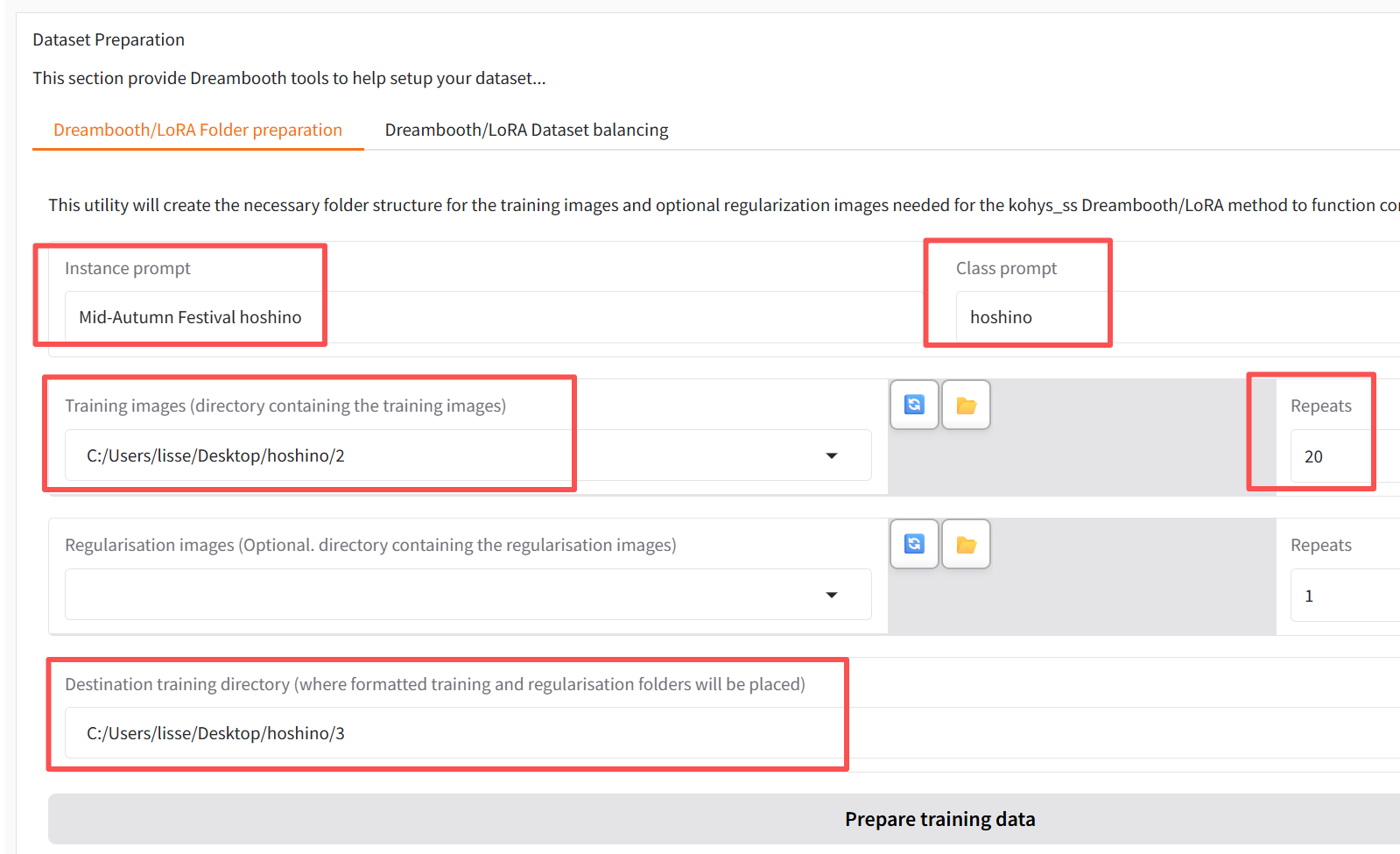
实例提示 (Instance Prompt):填写你为这套新服装创建的、独一无二的触发词。
类别提示 (Class Prompt):填写这个角色在模型中已经存在的、更广泛的类别。
点击生成后,会在指定目录生成三个文件夹img、log、model,分别是训练的图片,训练的日志和训练输出的模型地址。点击生成按钮下面的copy,可以自动将地址填写到上面的配置中。
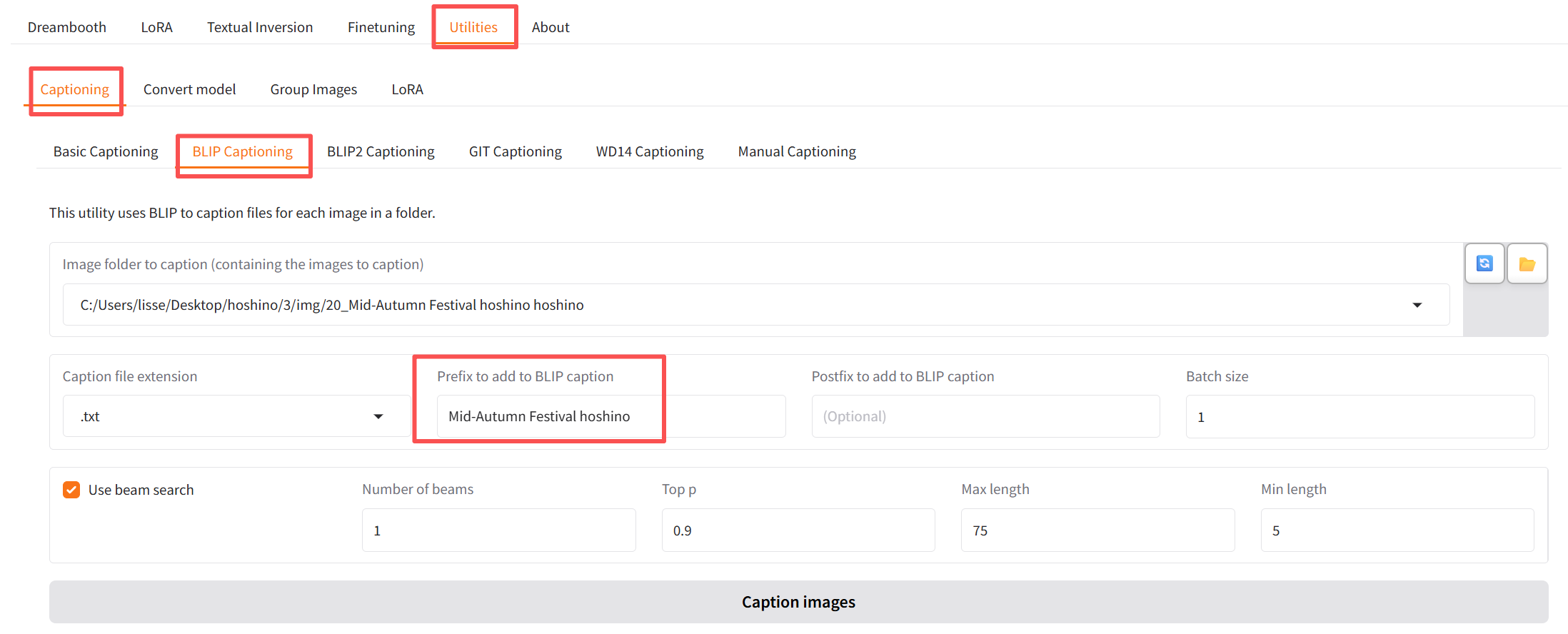
接下来就对img中的图片进行标注,先使用工具进行自动标注,首次运行会自动下载一个多G的模型,所以会等一阵子。就我这个中秋服饰的星野来说,提示词奇差无比!全部用gemini重写了。这个提示就是用来描述这个图片的,当之后外部引用这个lora,使用相同的提示词就能更偏向你训练的图片样式了。
之后回到lora的训练界面,下列是我的训练参数:
| 名称 | 值 | 说明 |
|---|---|---|
| Epoch | 10 | |
| Max train epoch | 0 | 不改成0,则会按照这个值来训练,直到损失没啥变动了 |
| Save every N epochs | 1 | 多少轮保存一次 |
| LR Scheduler | cosine_with_restarts | |
| Optimizer | AdamW8bit | 在效果和显存占用之间取得了完美的平衡,是目前的主流选择 |
| Learning rate | 0.0002 | |
| Text Encoder learning rate | 0.00005 | |
| Unet learning rate | 0 | 使用Learning rate的 |
| Max resolution | 1024,1024 | |
| Network Rank (Dimension) | 64 | 对于细节丰富的服装,64的Rank比32能捕捉更多信息 |
| Network Alpha | 32 |
这次训练大概用了一小时,之后就是测试阶段,在comfyui中使用[efficient]实现,搜索efficiency-nodes-comfyui进行安装。他会批量测试不同权重不同阶段模型的出图效果,最终形成一个二相图。这里先说下需要的四个节点:
- Eff. Loader SDXL:可以就选择下模型,正向反向提示词,其他不用动。
- KSampler SDXL (Eff):根据你选择的模型设置对应参数。
- XY Plot:啥参数都不需要改
- XY Input: LoRA Plot:X_batch_count的值代表你要测试多少个lora模型,下面的地址就是训练输出模型路径了。y轴参数是指定模型权重,从多少到多少,测试几个图,比如从0.6到1,则是5张图。
连线情况如下图:
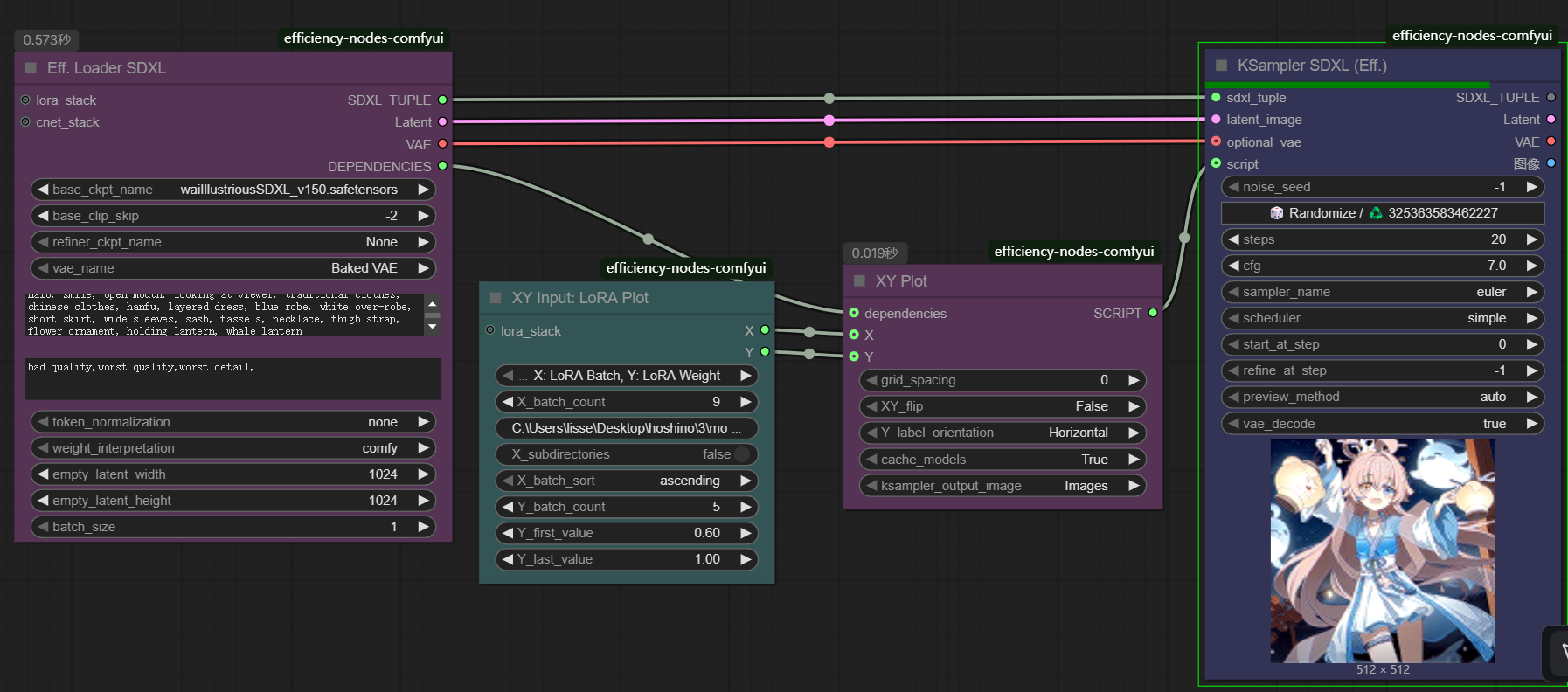
最终生成了一个横坐标是不同模型,纵坐标是不同权重

NSFW
现在的涩图生成,是无比简单,使用的wai-illustrious-sdxl模型也不分NSFW版本了,试着用大模型将骚话翻译成提示词,生成了几十张,效果还不错。
图生图
图片放大
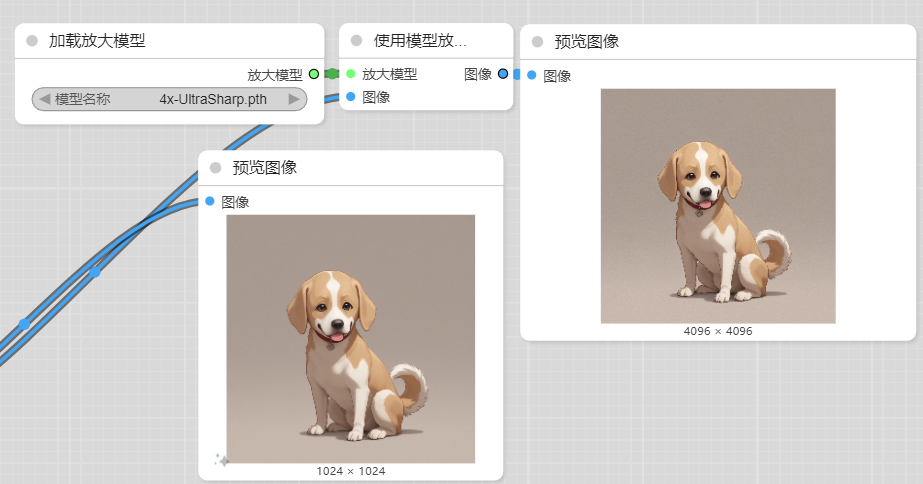
通过算法将低分辨率图像转换为高分辨率图像,我这里使用了RealESRGAN x4,可以直接在Manager中直接搜索下载,可以自己去模型站中找中意的下载放到ComfyUI\models\upscale_models。
流程也很简单,一个加载放大模型的节点,一个使用模型的节点
局部重绘
VAE编码器方式
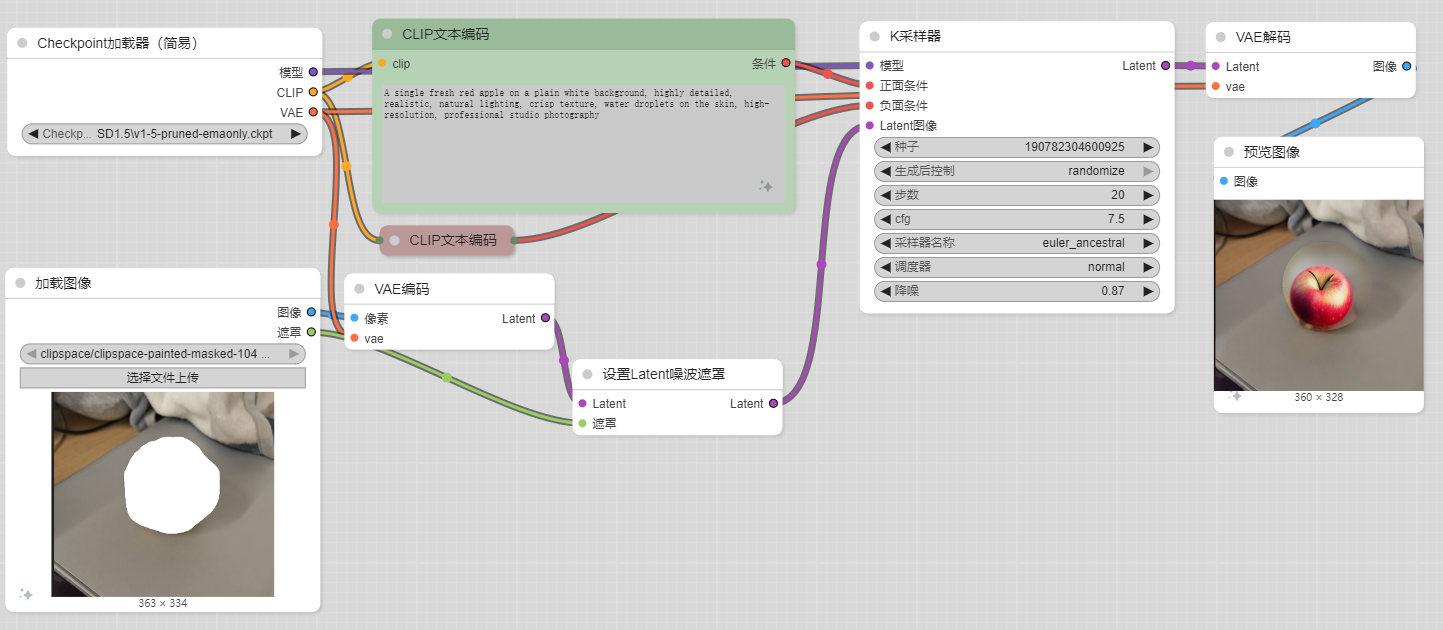
之前的latent组件组件中说过,Latent就像是底稿,这里将绘制了蒙版的图片作为底稿输入给了K采样器,使其在此基础上绘制选定区域。
外扩
在生成图片的时候很容易发生边沿截断了想要呈现的信息,仍然可以在Latent上做文章。将原本的底稿边沿增加新的区域,然后和局部重绘相似,让模型去在新增加的区域上绘制内容。
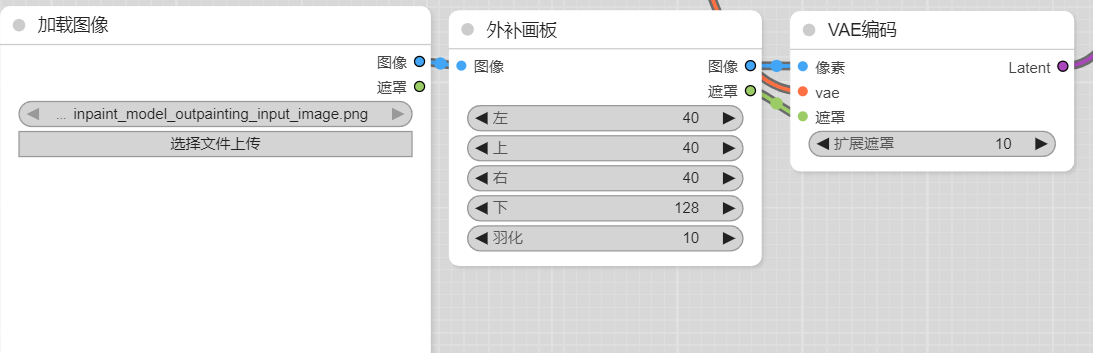
实际对人体外扩效果很不好,连接处非常割裂,之后再研究研究。
视频生成
试了试,5秒视频花了10几分钟,还是算了。