人脸识别
本文最后更新于 2022年12月6日 凌晨
对人脸识别的浅谈和基于框架的实现。虽然刚步入这个领域,但是也不知道会持续多久,所有记录下目前所知道的
1 浅谈
人脸识别实际上分为两个部分,人脸检测与人脸识别,首先在图中间找到脸,然后对脸进行特征提取,和库中的特征值进行比对,有没有接近的,通过给的阈值来判断是否认为图中人和库里的对象是一个人。库需要在识别前建立,保存了需要识别对象的特征值。
由上可以看出,人脸识别需要两个模型,一个检测人脸,一个特征提取。什么是特征呢,比如早上你在路上看到一个绿头发的人,那么下午再次遇到了一个绿头,你就会想是不是同一个人呢,我们将头发颜色作为了那个人的特征,当有足够多的特征就能区分更多的人。模型便是从人头像中获取这个特征值。
2 实现
从零开始对于我肯定不现实,首先那就是去找别人写好的架子,最先找到的是facelib,代码少,使用简单,我对其进行了应用方面的改版。之后就接触了facenet,用它完整实现了识别,但是识别速度不是很快,就去了解了一下部署,发现了PaddleInference,至此由最初选择的pytorch改为了paddle,先后尝试了face.evoLVe与insightFace。
下列都是一些零碎记忆,
2.1 改版的facelib
最开始最开始,我还啥都不懂时,对着github搜索栏填入face recognition,将感觉能直接玩的工程全部下下来,从中找到了最简单开箱即用的facelib。之后进行了改版,具体干了啥忘记了,readme第一行提供了fork的原版,选方便的玩。
模型云盘,提取码:1111
2.2 facenet
此仓库非常利于对识别应用的学习,和后面几个不同,没有进行层层封装,方便通过代码来了解实现过程。
基于此我搭建了一套完整应用,用于识别的客户端,通信服务器,应用的微信小程序。简答来讲就是因为只有本机有GPU,就把识别功能运行在本地,通过MQTT与服务器通信。一个用于对人脸库增删改查的平台,然后微信小程序用于拍照上传,获得识别结果。
然后进行各种测试,发现误识率比较高,有的时候会将奇怪的地方识别为头像,识别速度比较慢的问题。识别与检测问题只能靠更改模型来解决,于是有了后面了旅程,训练。
2.3 检查图片是否可以被打开
当批处理图片时,最好先对图片进行筛选,判断导入数据是否有不是图片的,干掉它。
1 | |
2.4 用paddlehub实现的人脸检测
最简单的人脸检测实现,看这名字也知道是paddle的,需要安装框架
使用的是pyramidbox_face_detection模型
环境安装:
1 | |
只会用到一个函数face_detection
1 | |
- images (list[numpy.ndarray]): 图片数据,ndarray.shape 为 [H, W, C],BGR格式;
- paths (list[str]): 图片的路径;
- use_gpu (bool): 是否使用 GPU;
- output_dir (str): 图片的保存路径
- visualization (bool): 是否将识别结果保存为图片文件;
- score_thresh (float): 置信度的阈值。
返回结果示例:
1 | |
示例代码,用于将一个文件夹中分好类的人脸图裁剪后放到新文件夹中
1 | |
2.5 face.evoLVe的paddle训练模型
原始仓库
实际是操作paddle文件夹,外面使用pytorch,环境还是那一套
- 对数据进行对齐,进入align文件夹执行,对齐前可以用上面的函数去除掉无法打开的图
1
python face_align.py -source_root=D:/code/face/bank/my -dest_root=../data/output_align - 设置参数,最外层的config.py文件,主要修改下列参数,其他的根据自己情况改吧。
1
2
3
4
5DATA_ROOT = './data/output_align', #输入数据的地址
MODEL_ROOT = './data/train', #模型输出地址
BATCH_SIZE = 128,#没出处理的图数量,和使用的显存有关
NUM_EPOCH = 60 #进行多少轮的训练,拟合情况设定
VAL_DATA_ROOT = 'data/val_align', - 开始训练,训练数据我从aligned_vggface2_36w中和web_face两个集合中各取了一万多张图,共507个分类,测试则直接用lfw-align-128数据集,5,751个分类,1W3张图,
1
python train.py
acc折线图看得出效果不好
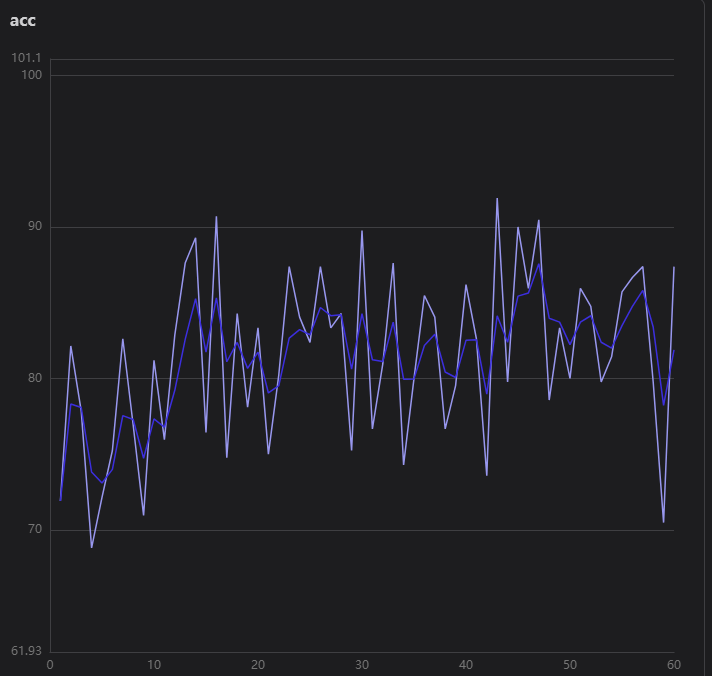
loss从26降低到16,训练结果:

这个模型肯定是不合格的,得继续炼丹,这方面是新手就不深谈了。
2.6 InsightFace的Paddle方式使用
InsightFacePaddle就是paddle对insightFace的部署,就和前面face.evoLVe工程中的PaddleInference-demo类似。
安装文档是可以直接通过pip安装
1 | |
然后通过命令直接使用,用过-h查看参数
1 | |
这边还是将仓库克隆下来好一点,源码实际上就insightface_paddle.py一个文件,demo中是示例图片。
模型支持三种:检测的BlazeFace,识别的ArcFace和MobileFace,传参后会自动下载,无需去找模型。
下面是官方示例:
建库,也就是之前那个人脸库
1 | |
检测
1 | |

识别,直接对图片进行特征提取匹配
1 | |
检测并且识别
1 | |
接下里就是改一改,识别自己的图片。首先在demo文件夹中添加my/lib文件夹,将对齐的图片模仿\demo\friends\gallery放在,添加label.txt。注意这个文档格式,地址和名称直接用tab,末尾不要添加多余换行
1 | |
使用命令建库
1 | |
然后在demo\my下建立query文件夹用于放在准备识别的图,output放在识别结果。修改一下默认值,懒得贴长命令
1 | |
进行识别
1 | |

6个人找到了2个人。额。。不晓得最相近人脸的值是多少,阈值只能瞎调看看。之前的facenet可以输出不同脸的差分值,然后看看识别后这个人最相近的人脸差值多少,就很方便调阈值。
将检测阈值调成9,识别阈值调成4,多找到一个。将识别模型修改为ArcFace。需要生成index.bin,否则回报下列错误
1 | |
结果又多识别出一个人 - -|
应用体验暂时就这么,还是先去看看InsightFace。
2.7 InsightFace
仓库都有13K的start了,之前由于发现是mxnet就完全没去关注,最近发现居然转pytorch了,又看到他也支持paddle,正好目前在用,就来试试。
2.7.1 arcface_paddle
安装有中文文档,这里补充下,在执行下面命令
1 | |
如果报错
1 | |
是因为test_architectures.py中地址用的是configs/xxx/xxx,找不到仓库根目录的configs,改下地址就好
上面那个insight-face-paddle实际上在这里面也有,对应文件在insightface\recognition\arcface_paddle\tools目录下的test_recognition.py,对比了下代码,test_recognition中裁剪掉了生产人脸库bin的功能,其他都是一样的。
但是感觉用起来相当的麻烦,用原版看看了。
2.7.2 原版
环境
可以直接pip安装,也可以直接调用insightface\python-package\insightface目录下的代码
仓库中也有个readme说明。
运行环境:
1 | |
insightface包的依赖,如果不通过pip install Cython insightface安装则需要手动去安装下面的包
1 | |
如果之后执行报错
1 | |
需要进入insightface\python-package\insightface\thirdparty\face3d\mesh\cython目录下安装setup
1 | |
试用
在insightface\python-package目录下有测试文件test.py,填入
1 | |
然后执行
1 | |
打印一大堆,然后生产output.jpg

如果报错
1 | |
下载对应缺少文件,提取码u367,将zlibwapi.lib放到NVIDIA GPU Computing Toolkit\CUDA\v11.6\lib\x64下,将zlibwapi.dll放到NVIDIA GPU Computing Toolkit\CUDA\v11.6\bin下
使用
对比两张脸的差距
1 | |
检测群体照,代码参考来源,感谢此大佬的博客,唯一找到的应用示例,不晓得为啥官方没给个完整的例子
1 | |
使用了几张集体照来测试,效果非常好,库中对象都识别出来,并且没有误识别的问题。
可能遇到的问题
InsightFace paddle执行示例时报错
1
2
3File "D:\Anaconda3\envs\paddle\lib\site-packages\numpy\core\fromnumeric.py", line 57, in _wrapfunc
return bound(*args, **kwds)
ValueError: kth(=-1) out of bounds (6)–cdd_num参数设置问题
1
2
3
4
5
6parser.add_argument(
"--cdd_num",
type=int,
default=6,
help="The number of candidates in the recognition retrieval. Default by 5."
)使用InsightFace的警告
1
To use the future default and silence this warning we advise to pass `rcond=None`, to keep using the old, explicitly pass `rcond=-1`.没啥关系,看着烦可以取消
1
2import numpy as np
np.warnings.filterwarnings('ignore')或者如描述添加
1
lstsq(A,b,rcond=None)