whisper语音转文字
本文最后更新于 2026年4月17日 早上
本文主要记录用whisper将音频转为文字的流程
1 简述
Whisper是OpenAI开发的一款自动语音识别(ASR)系统。ASR系统的主要目标是将人类的语音信号转换成可理解的文本。Whisper不仅可以提高现有语音识别技术的性能,还可以在各种声音环境和不同口音的场景中保持较高的准确性。(这段话是gpt生成,简而言之就是个开源、较高准确率的语音转文字工具)
2 环境
需要Python 3.8-3.10,我这儿就安装3.10了。仍然用conda
1 | |
pytorch这里建议如果有GPU那就安GPU版本的,速度差距巨大
1 | |
安装ffmpeg,我是windows,直接下下来后对bin目录配置环境变量。然后在控制台输入ffmpeg看是否识别了此命令
安装whisper
1 | |
更新的话:
1 | |
3 使用
1 | |
可选择的模型:

如果你使用的是cpu,那么可能出现警告:
1 | |
在命令后面添加参数: –fp16 False,来取消。
如果报啥找不到指定文件,那可能是你ffmpeg环境没弄好。
这里用两首歌来试试,支持语言可参考这里,然后用gpt转化为中文,效果还是不错
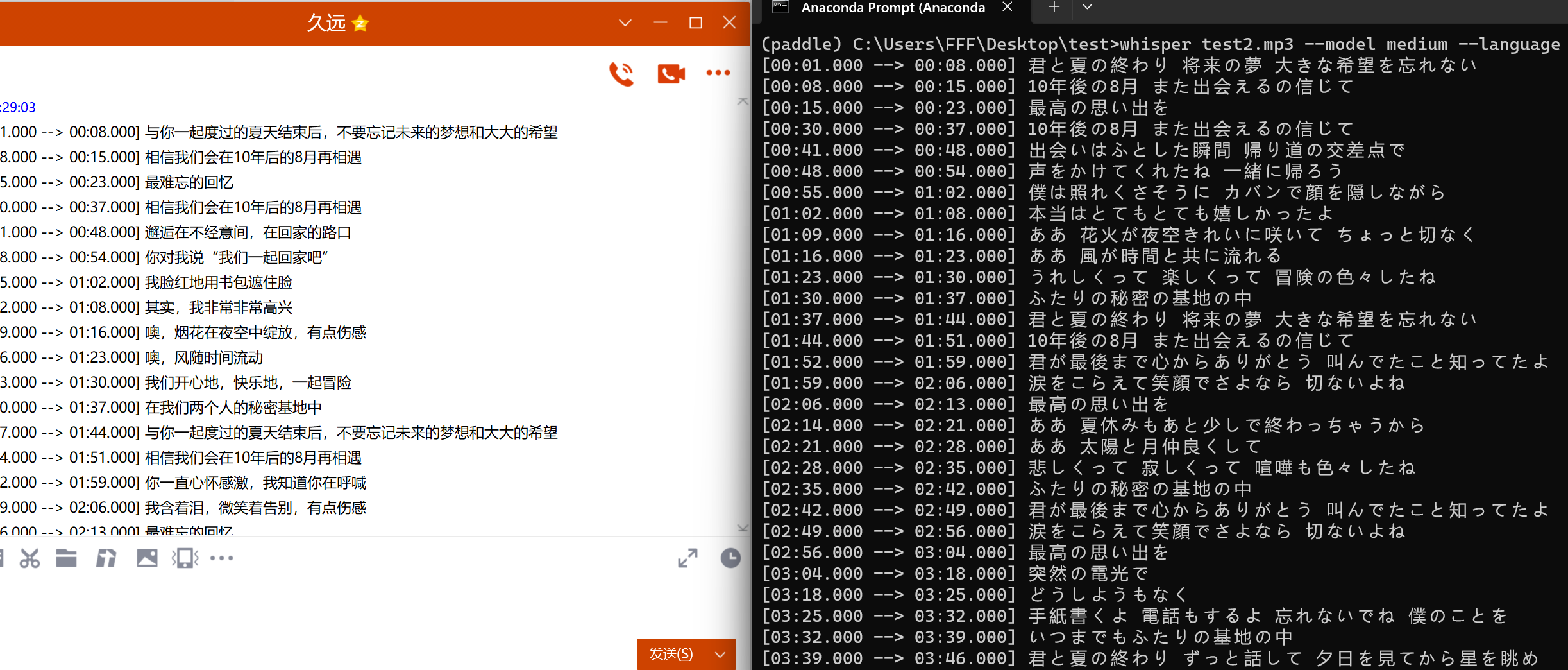
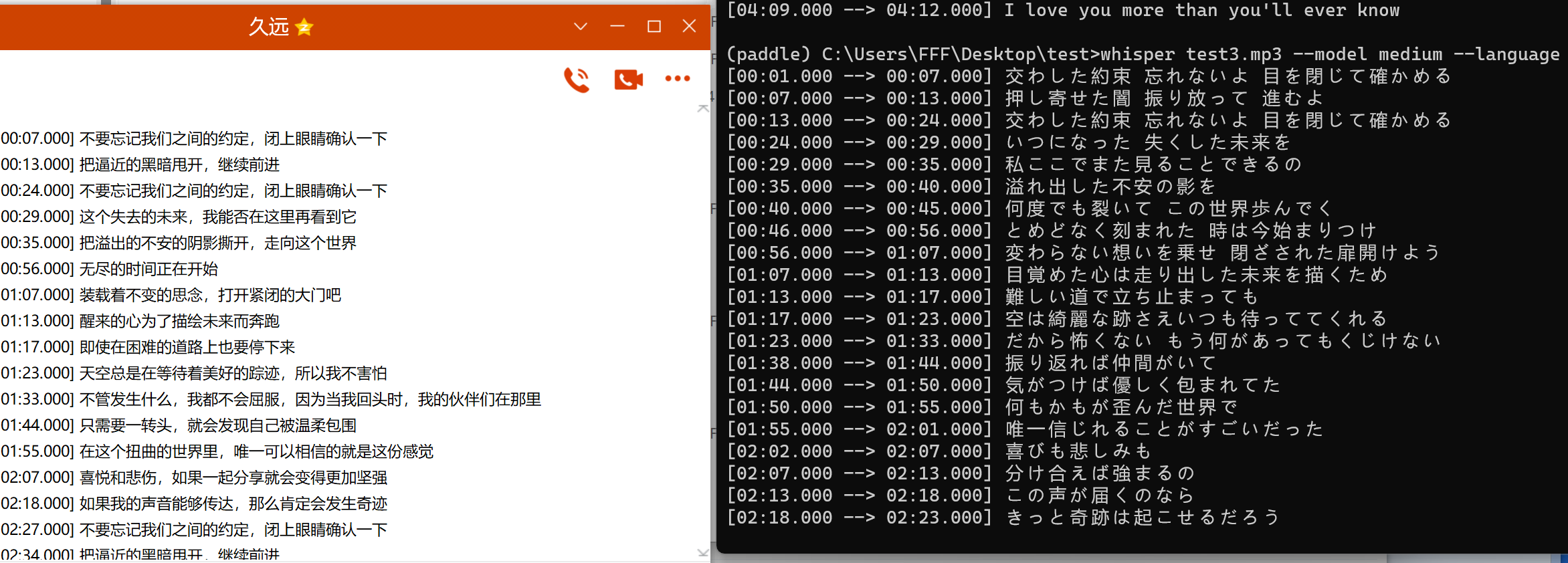
whisper语音转文字
https://blog.kala.love/posts/7779e518/