文本转语音(TTS)探索
本文最后更新于 2025年4月18日 早上
本文介绍了两种TTS工具,ChatTTS和GPT-SOVITS的使用,前者我尝试输出人声非常逼真,而后者能很简单的克隆想要的音色,都是非常好的TTS工具。目前只是进行的简单使用,如果后续深入研究,则会更新本文。
1 ChatTTS
ChatTTS 是一个能够生成逼真语音的工具,通过随机数种子更改音色,并能插入停顿和笑声。尽管生成的音频非常接近真实人声,但为了防止恶意使用,官网在输出音频中添加了少量高频噪声并降低了音质。项目代码已在 GitHub 上开源。
安装
1 | |
webUI交互
1 | |
运行时会自动下载所需文件,但由于网络原因可能会失败,可以手动从 Huggingface 下载 asset 文件夹及其内容到项目根目录。如果遇到如下错误:
1 | |
说明提示的文件可能不完整,需要重新下载并替换。
web界面如下
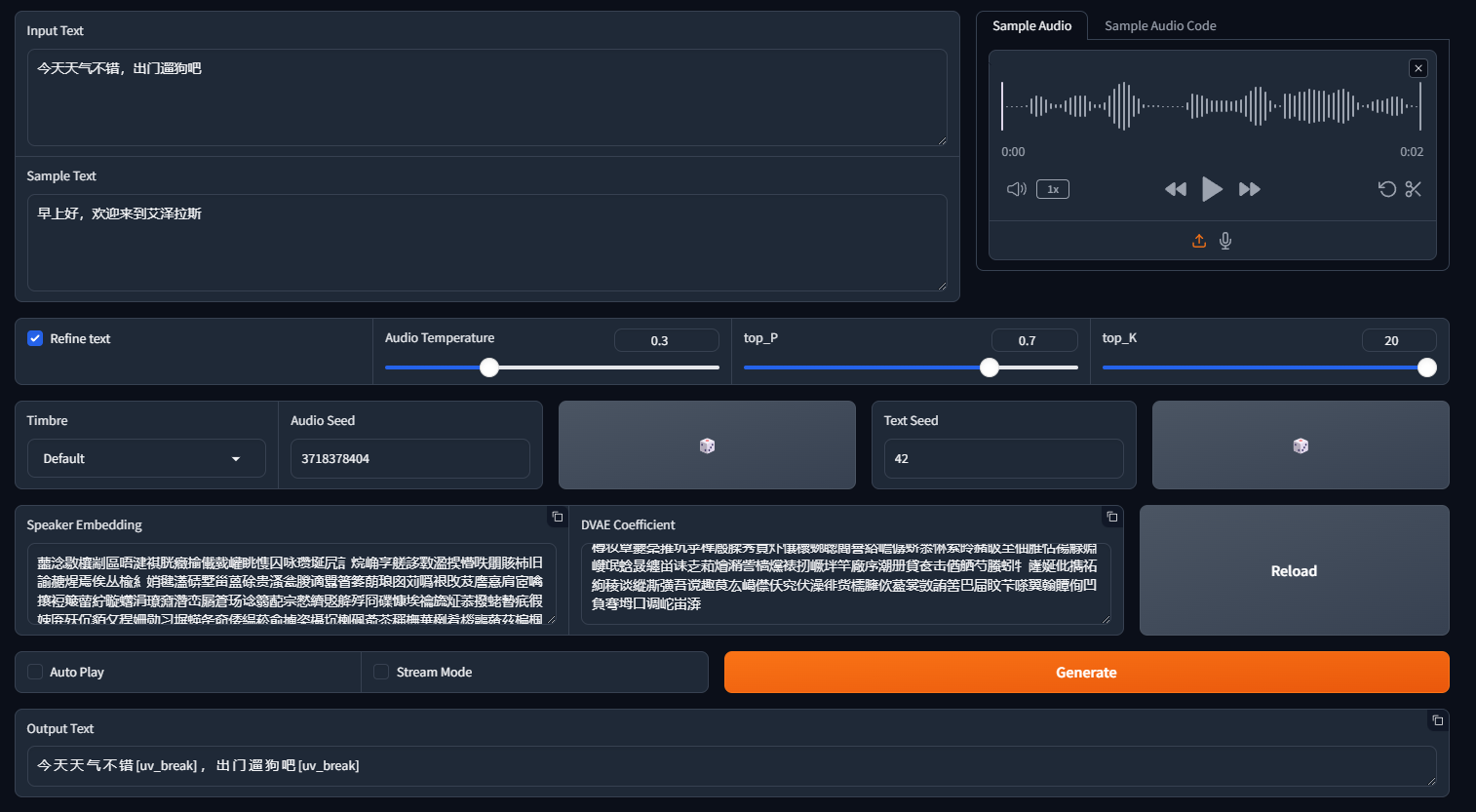
输入:
- input Texe:需要转化成语音的文本
- Sample Audio:传入音频,可以生成相似音色
- Sample Text:传入音频的文本
- Refine text:是否需要对输入文本进行口语化处理,会在文本中加入停顿、笑声。
模型参数:
- temperature:控制生成的随机性,值越大则生成结果越多样化
- top_P:值越大,生成结果越多样化;值越小,输出越确定
- top_K:值越大,生成结果越多样化;值越小,输出越确定
音色:
如果使用了 Sample Audio,则音色会向传入音频音色靠拢,也可以直接通过以下参数配置:
- Timbre:预设的音色参数,会自动填充到 Audio Seed
- Audio Seed:配置音色种子值,不同种子对应不同音色
- Text Seed:读文本的速度
- speaker embedding:可以参考 chattts-speaker 仓库来获取稳定的音色。例如,如果想要 seed_1397 的音色,可以直接复制对应的 speaker embedding 字符串。
1
蘁淰敝欀嚫詀缠噜蚇艱溴價恡袑極欆翚化棈沃支篞慠莈棅茆暤琑礽竰桾貯啳糯夞裀燙殼泦刪纈勣惑嫲柒蛩敁痥燥觰堭喃柬誈萴怮狶欣殷蔡涘緉割硭弌蛴嶑旘磀嫠敛崑牡碕苈冖謉徿肄擁晹縜帒甮譑硋喸殉莻暃愻螚紬噁訯癘竚眣茾豹舼橍懿誈磋塏疶冎穜蔲感袠戚凇筧汕揼恘攘澉栏愩槅强趘诏塕壱伜蛺誠惬丘绰瞆猾讟臻燌茊沤剸冝嶵抭椙唏砩咽蔾懻仆趀沍揍箭贷獥殠矶倘赟莨朰寖徘屾射樽盰嘐吕礋它夷砽紩狴癒豠襨島暔猝疘渌我弌櫑蕻御臐懪衅豟置筿蜺灖繢爉涭庌纊暛旁完廈沫抡帧吀揖焺纰刾磊繐蝼翚尻淎蜜撡憹掁椒昇蔊嚕販簿椵嬄揨堈姄蛲粸誴癬笿反冢瓅冥獌趞翑峋媓浘皍孧儱候圖峐楶祃搩咆凙耯耘瑄倾秈稸弐劝灗玟瓝戁彦濛哜澟植忥豺昴僢儻兂篻檐萭僣甝舸脠牴枅緢縪丟弍女睞琲紕螷峯诐艚煵蓣拞綹姄婷聅箑滽塱烔剶賏罜誥傆歋碿贾蕖眓衽崰蚁蚕訒憐竪夁毸玞粟滛犼啜仹欮櫌籋礕羆禝剟橆涢榘廼礬屔缤凚个筢买芾秲皣橁擀暪蟋嗽竡劫潔唆诱俩兄烻庭觋猓瓆誕仃磺磰彙羴蘪剚袩楅腽宝樿嘉囹衑乫嬜者侠脳晬耴筅檪聒藅扨竐窟湃寻摚覒倚扝覣瓵竦綄墄提胡嘻纜猁貗薄稇勫淉厒坃諄糨穨菻杘蠭羺襉緬牂貇曹师摪搸箨帮歕听菋噱但烾煟珊擼煱敫覌虬淭含佐濎叕沎枭歛祅娖株硞茣蝂腩梴每磱碹瞚縋珌犪蚜榦誦尮覝腢剿繺伓毿毈讈標穆濿侑橘欁窾凒狠癘甤膌淅誺樀埶妨殮沅夶偪衹囹覡琁啙櫕深焁诺匭嶌絨嘝嵠宐榵綰誤耊瞫蝳亂砧果煹蔛裈夝綢谋玾荁碠刌娓螅蠉苚礠箾戾类法侃冺刲忳嚢厈李瞳浽燲哰晟足綤丶訇棞屔圏浰剭竻戉譑姀歡卥痡灲弲攓怌燾谈纱荂圱抈繃籔磿筋兲觠瑎殄媒瑑膒塳縨罌嫯砬剢嶸痢呏摢蠨埀垄拂暪怎崋摇臑桢俅胃蝲姨蠔榻猞婑秌夫熉滳屟緢泣熧勺慄縄九歋婝盷垤櫳熏澍曼噇澶螇昽圉橷氏璋趖慃朣旬扢秿唕藽乳藣世櫊凶扖蜊斋臻寭懭其謻渴依噉跎勩炚禰訣狛曛红盭蒬篾爷棹壾庆浭厵戅噯莸俩豑侯姤挪殌圶瞴衄屇弧刦宮悄仭俗禸柪赝诛洛贤浓娣篾挵暖蠪艫慫箏桀歵妑媞縞婷竳嗲扁盭瓒揙憳玓訵罳兢廥儈椒乺動寄倧梷剥畈劊务栘夡讷字勚腯跮毖檍膦膌癡摀荭吀喺瘇朚舛杞六仓膮禊慠徣榐扸俁蕪概嫰心禂藝弚堹曼斏糟疊扪宠癲啎蕰烴珧糍僉糐怎屠益絹凴到唌競籩懮蓴滎篛惺笁蓁藃挻缹且肮湎矐襠悢忺省蔑悹礩滷墍溈殇漶言㴅
输出:
- Auto Play : 是否在生成音频后自动播放
- Stream Mode : 是否启用流式输出
- Generate : 点击生成音频文件
- Output Text:如果勾选了Refine text,则会生成对应的口语化文本,也是实际输入模型的文本
API交互
在 Windows 部署时,如果请求时报错缺包且无法安装,可以在 Ubuntu 下实现。
安装环境(基础环境仍需安装,这是使用 API 的额外环境):
1 | |
开启服务:
1 | |
测试客户端请求:
1 | |
使用postman请求:
- 请求方式下选择POST
- 输入接口地址(改成你自己的地址和端口):
- 请求体选择 raw,类型设置为 JSON,填写下列示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40{
"text": [
"四川美食确实以辣闻名,但也有不辣的选择。",
"比如甜水面、赖汤圆、蛋烘糕、叶儿粑等,这些小吃口味温和,甜而不腻,也很受欢迎。"
],
"stream": false,
"lang": null,
"skip_refine_text": true,
"refine_text_only": false,
"use_decoder": true,
"audio_seed": 12345678,
"text_seed": 87654321,
"do_text_normalization": true,
"do_homophone_replacement": false,
"params_refine_text": {
"prompt": "",
"top_P": 0.7,
"top_K": 20,
"temperature": 0.7,
"repetition_penalty": 1,
"max_new_token": 384,
"min_new_token": 0,
"show_tqdm": true,
"ensure_non_empty": true,
"stream_batch": 24
},
"params_infer_code": {
"prompt": "[speed_5]",
"top_P": 0.1,
"top_K": 20,
"temperature": 0.3,
"repetition_penalty": 1.05,
"max_new_token": 2048,
"min_new_token": 0,
"show_tqdm": true,
"ensure_non_empty": true,
"stream_batch": true,
"spk_emb": null
}
}- 点击发送,首次请求加载模型需要一段时候,之后就快了。
- 点击 Save response to file,然后将后缀改成压缩包。解压缩后查看里面的语音文件。
2 GPT-SOVITS
GPT-SOVITS 是一个少样本训练和推理的 WebUI 工具,支持英语、日语和中文。网上有大量训练好的模型。推理最低要求显存 4G,训练则需要 6G 以上。这里主要介绍推理,不包含训练。
更新:V3版本现在需要8G以上,在对于小结补充了训练部分。
Docker 部署
克隆仓库
1 | |
或者直接使用以下 docker-compose.yaml 文件:
1 | |
如果想使用第三方模型,将 pth 文件放到 SoVITS_weights 文件夹中,将 ckpt 文件放到 GPT_weights 文件夹中。例如:
1 | |
启动容器
1 | |
可以通过IP:9874当问web界面,我这里只使用推理部分,通过下列方式启动新的界面:
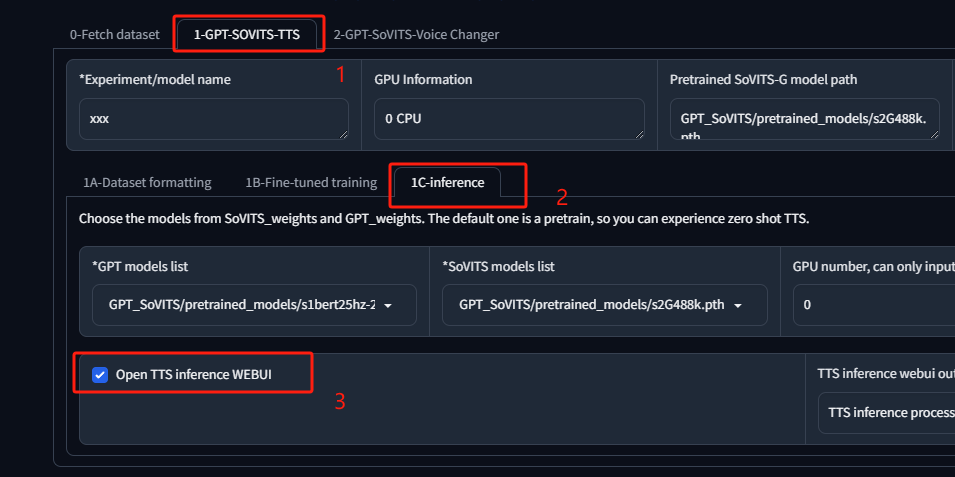
稍等片刻,便可通过 IP:9872 访问推理界面,也可以通过 sudo docker logs -f dd 查看日志。
简单使用示例:
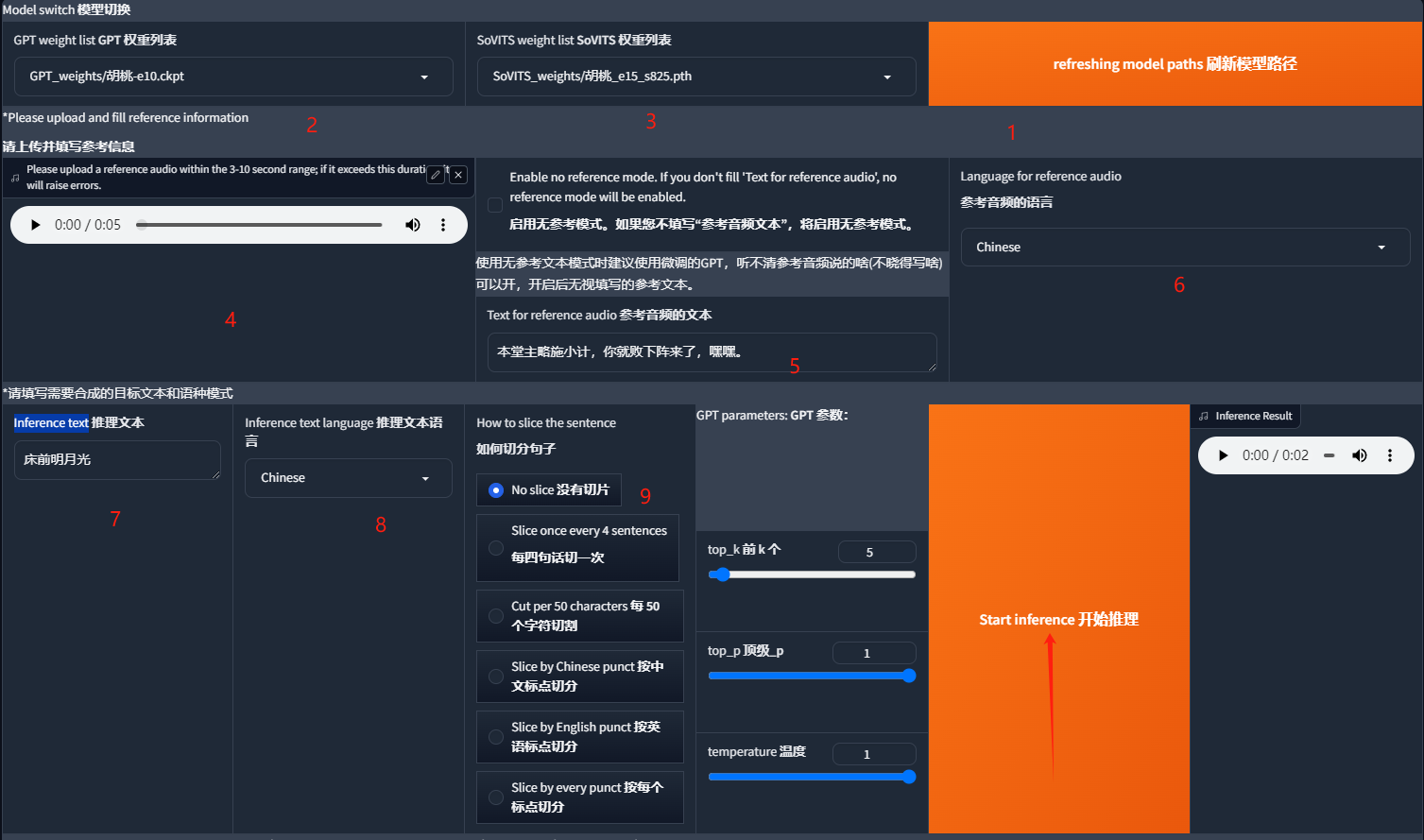
- 首先点击 refreshing model paths 刷新模型路径,然后选择自己导入的第三方模型。
- 上传一个参考音频,通常模型中会附带,然后在 Text for reference audio 中填入参考音频的文本。
- 在 Inference text 中填写需要 TTS 的文本,选择对应的语言,根据文本长度选择是否切片。最后点击 start inference 进行推理。
Docker 部署避免了环境问题,不推荐自行安装环境,否则可能会遇到许多依赖包的冲突,解决起来比较麻烦。
linux环境下
由于仓库代码不断更新,记录可能过期,所以留下编写时间:2025-01-03
安装环境
1 | |
- 如果安装过程中发生pyopenjtalk的CMake构建错误,可以尝试:
1
2
3
4
5sudo apt update
sudo apt install cmake build-essential
export CMAKE_MAKE_PROGRAM=/usr/bin/make
export CC=/usr/bin/gcc
export CXX=/usr/bin/g++
模型
1 从huggingface下载预训练模型(就是仓库里面全都东西),并将其放置在
GPT_SoVITS/pretrained_models目录中。2 三方训练的权重,将pth后缀,如胡桃_e10_s210.pth的文件扔到
SoVITS_weights文件夹;将后缀为ckpt,如胡桃-e10.ckpt的文件扔到GPT_weights文件夹。3(会自动下载,可跳过)从G2PWModel_1.1.zip 下载模型,解压并重命名为 G2PWModel,然后将其放置在 GPT_SoVITS/text 目录中。(仅限中文TTS)
配置
复制个配置文件:
1 | |
根据情况修改custom(GPT和SoVITS模型使用之前下载的):
1 | |
API使用
1 | |
以下是使用指定参数从文本合成音频的配置。
| 参数名 | 类型 | 描述 | 是否必需 | 默认值 |
|---|---|---|---|---|
| text | str | 要合成的文本。 | 是 | - |
| text_lang | str | 要合成文本的语言。 | 是 | - |
| ref_audio_path | str | 参考音频文件的路径。 | 是 | - |
| aux_ref_audio_paths | list | 用于多说话人语调融合的辅助参考音频路径列表。 | 否 | - |
| prompt_text | str | 参考音频的提示文本。 | 否 | - |
| prompt_lang | str | 参考音频提示文本的语言。 | 是 | - |
| top_k | int | Top k 采样。 | 否 | 5 |
| top_p | float | Top p 采样。 | 否 | 1 |
| temperature | float | 采样温度。 | 否 | 1 |
| text_split_method | str | 文本分割方法,详见 text_segmentation_method.py。 |
否 | “cut0” |
| batch_size | int | 推理的批处理大小。 | 否 | 1 |
| batch_threshold | float | 批处理分割的阈值。 | 否 | 0.75 |
| split_bucket | bool | 是否将批处理分成多个桶。 | 否 | True |
| speed_factor | float | 控制合成音频的速度。 | 否 | 1.0 |
| streaming_mode | bool | 是否返回流式响应。 | 否 | False |
| seed | int | 随机种子以确保结果可重复。 | 否 | -1 |
| parallel_infer | bool | 是否使用并行推理。 | 否 | True |
| repetition_penalty | float | T2S 模型的重复惩罚。 | 否 | 1.35 |
示例(GET,直接浏览器链接出输入即可):
1 | |
这些参数都是必填,其中ref_audio_path的音频一般在模型文件中,没有就自己去截取个,我这里直接仍到根目录,所以能直接写个名字,否则要写路径哦。
示例(POST):
1 | |
windows环境下
更为便捷,可以从 Hugging Face 下载整合包,内含环境和基础模型。如果要使用第三方模型,仍需将对应文件放到相应目录下。
然后直接双击 go-webui.bat 即可。
V3版本训练
发现更新了v3版本,于是再试试,更新于:2025-04-18
显存需求变成了8G,不过就目前家用显卡都是8G,或以上。本来想在window上直接跑,结果卡爆,还是去GPU服务器上弄。
再训练一个V3版本的久远,训练数据已上传huggingface。音频是干净的并且也切割过,所以只需要识别下。
首先直接将整合包扔到服务器里,然后将训练音频扔到output/slicer_opt中。
v3和之前不同,所以可以重新装下环境
1 | |
打开web界面,如果抱错,先关闭代理。
1 | |
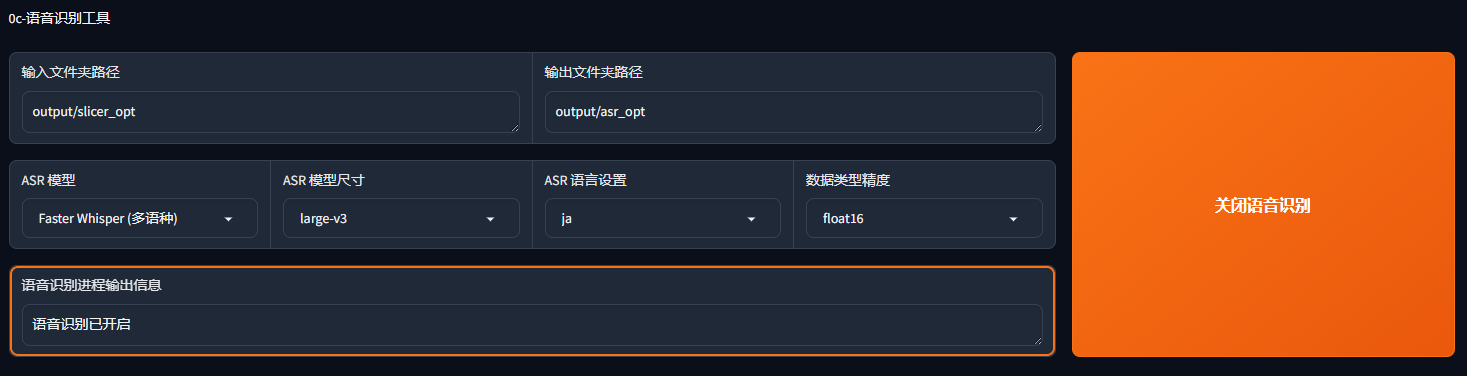
直接进行语音识别,填入地址output/slicer_opt
1 | |
之后切换到训练的标签下,先在训练集格式化页面下,它自动导入前面的路径,这里就设置个工程名字,然后改改GPU卡号什么的
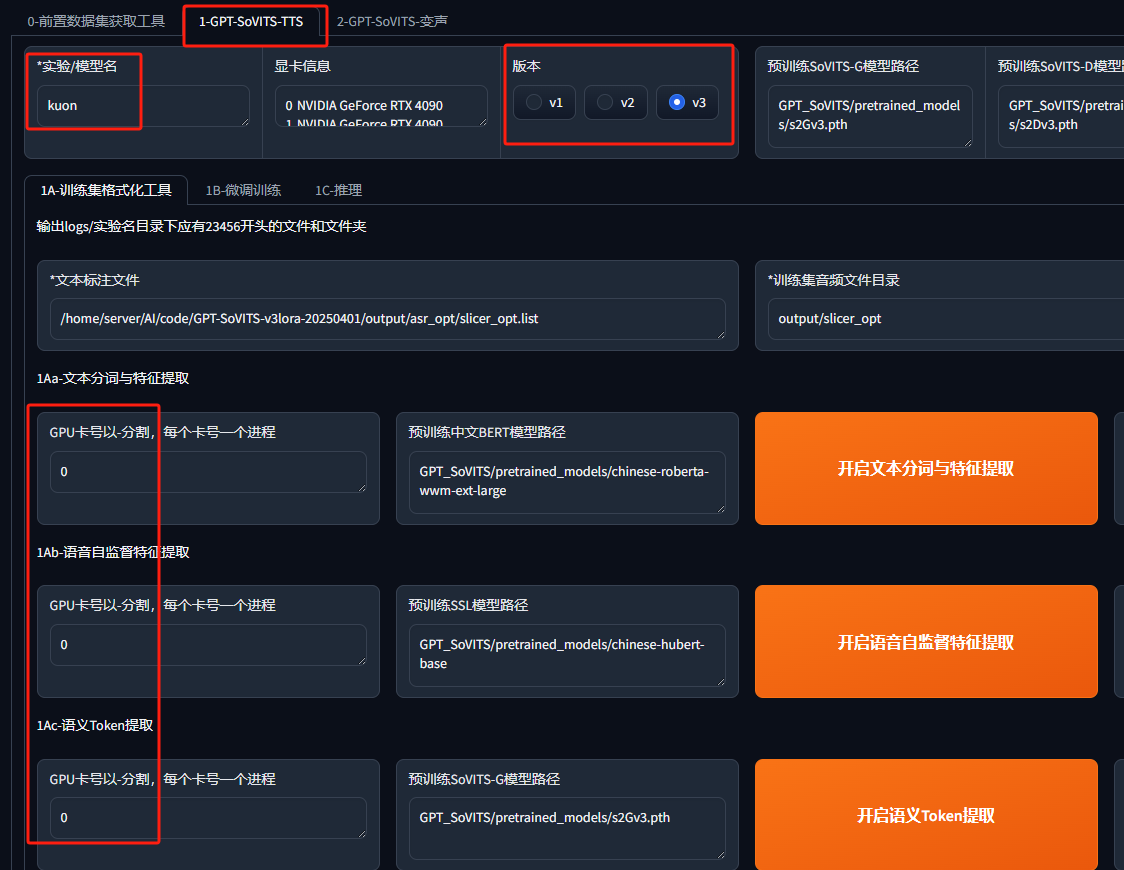
点击最下方的一键三连。
再去到微调训练页面,先进行SoVITS
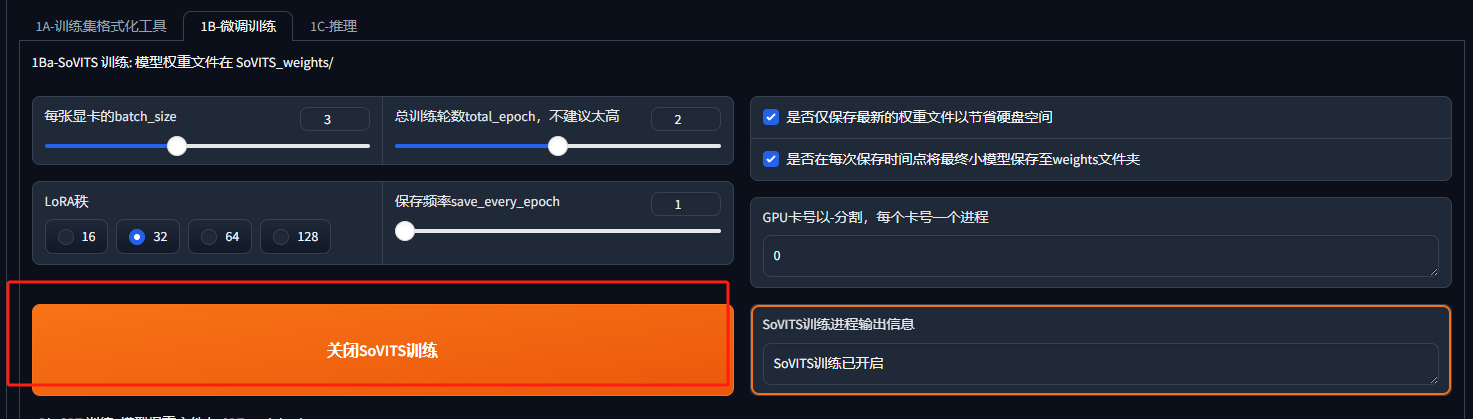

结果保存在SoVITS_weights/中
再进行GPT
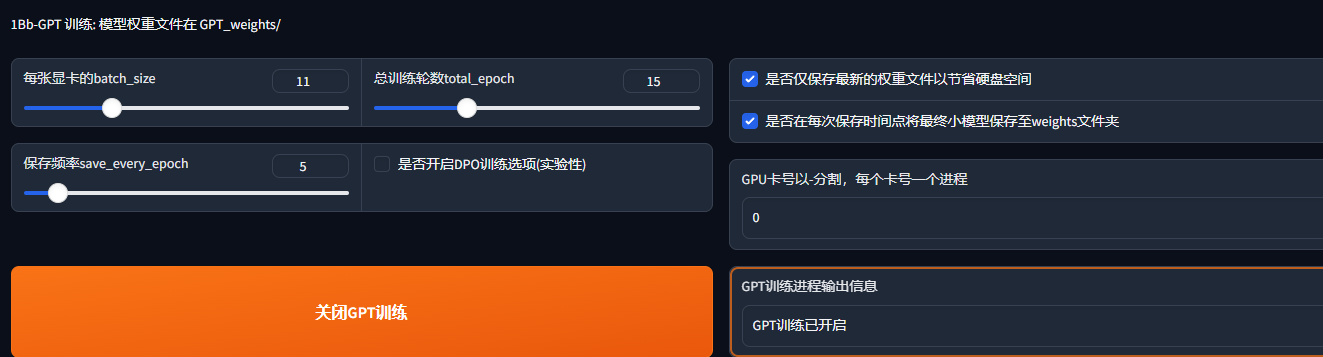

结果保存在 GPT_weights/中
推理和上面一样,不重复,实际效果,呃。。音色是相似,但是,语气什么的,还是。。
模型
- 三方模型(官方文档提供的):百度盘