GCC编译流程
本文最后更新于 2026年4月17日 早上
1. 前言
本文主要说明使用gcc编译一个hello world程序时的四个步骤,预处理(Prepressiong)、编译(Compilation)、汇编(Assembly)、链接(Linking)。
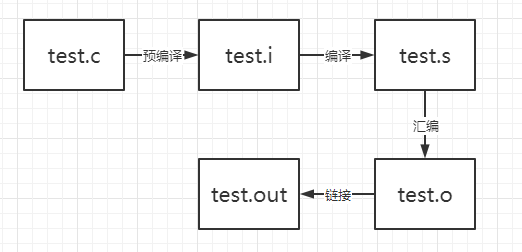
2. 预处理
主要是处理源文件中以#开始的预编译指令,经过预编译后的.i文件不包含任何宏定义,所以的宏都被展开。
使用以下例程来测试
1 | |
使用gcc -E命令生成.i文件
1 | |
test.i
1 | |
3. 编译
编译过程是把预处理完毕的文件进行词法分析、语法分析、语义分析及优化后生成相应的汇编文件。
- 词法分析:将源代码的字符序列分割成一系列的记号,记号分为关键字、标识符、数字、字符串、特殊符。
- 语法分析:由语法分析器生产的语法树就是以表达式为节点的树。
- 语义分析:仅能分析静态语义,给语法树的表达式标识了类型。
- 中间语言生成:源码级优化器会对源代码进行优化。
- 目标代码生成与优化:编译器后端(代码生成器、目标代码优化器)。
示例代码不变,测试命令改为
1 | |
test.s
1 | |
4. 汇编
汇编器是将汇编代码转化成机器可执行的指令
1 | |
这里将生成目标文件,包含程序指令和程序数据,代码段属于程序指令,数据段和bss属于程序数据。
- .data保存已初始化的全局变量和局部静态变量
- .bss段未初始化的全局变量和局部静态变量,只是预留位置,没有内容,不占空间。
- .test代码段
- .rodata只读数据段,就是一些常量
- .comment注释信息段
结构分析需要使用到objdump,这个工具是和编译器配套的
1 | |
| 命令 | 说明 |
|---|---|
| -f | 显示objfile中每个文件的整体头部摘要信息 |
| -h | 显示目标文件各个section的头部摘要信息 |
| -j name | 仅仅显示指定名称为name的section的信息 |
| -s | 尽可能反汇编出源代码,隐含了-d参数 |
| -d | 反汇编 |
示例代码:
1 | |

1 | |

5. 链接
链接的过程主要包含地址和空间分配、符号决议(Symbol Resolution)和重定位。需要将所以目标文件链接起来生成可以在特定平台运行的执行程序。
1 | |
GCC编译流程
https://blog.kala.love/posts/586509d0/