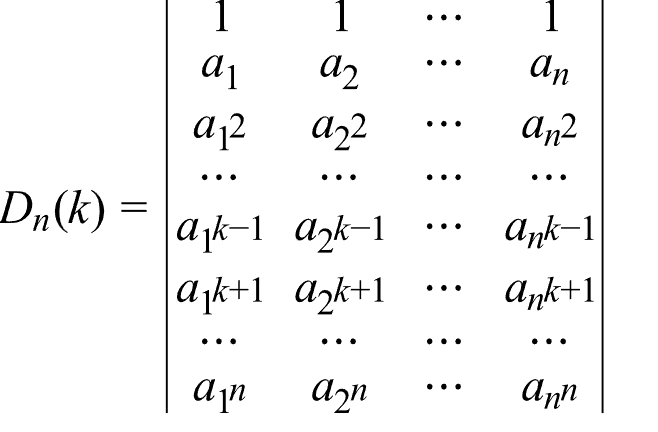1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
| import os
import tempfile
import numpy as np
import cv2
import time
from pathlib import Path
from fastapi import FastAPI, File, UploadFile, HTTPException, Request, Depends, Header
from fastapi.responses import JSONResponse
from onnxruntime import InferenceSession
from pydantic import BaseModel
from models.ocr_model.utils.inference import inference as rec_inference
from models.det_model.inference import predict as det_inference
from models.ocr_model.model.TexTeller import TexTeller
from models.det_model.inference import PredictConfig
from models.ocr_model.utils.to_katex import to_katex
app = FastAPI(
title="OCR识别接口",
description="目前对接了Paddle的通用OCR模型,和TexTeller的公式识别模型。",
version="1.0.0"
)
CHECKPOINT_DIR = os.getenv('CHECKPOINT_DIR')
TOKENIZER_DIR = os.getenv('TOKENIZER_DIR')
SERVER_PORT = int(os.getenv('SERVER_PORT', 8000))
NUM_REPLICAS = int(os.getenv('NUM_REPLICAS', 1))
NCPU_PER_REPLICA = float(os.getenv('NCPU_PER_REPLICA', 1.0))
NGPU_PER_REPLICA = float(os.getenv('NGPU_PER_REPLICA', 1.0))
INFERENCE_MODE = os.getenv('INFERENCE_MODE', 'cuda')
NUM_BEAMS = int(os.getenv('NUM_BEAMS', 1))
USE_ONNX = bool(int(os.getenv('USE_ONNX', 0)))
if NGPU_PER_REPLICA > 0 and INFERENCE_MODE != 'cuda':
raise ValueError("--inference-mode must be cuda or mps if ngpu_per_replica > 0")
class TexTellerRecServer:
def __init__(self, checkpoint_path: str, tokenizer_path: str, inf_mode: str = 'cpu', use_onnx: bool = False, num_beams: int = 1) -> None:
self.model = TexTeller.from_pretrained(checkpoint_path, use_onnx=use_onnx, onnx_provider=inf_mode)
self.tokenizer = TexTeller.get_tokenizer(tokenizer_path)
self.inf_mode = inf_mode
self.num_beams = num_beams
if not use_onnx:
self.model = self.model.to(inf_mode) if inf_mode != 'cpu' else self.model
def predict(self, image_nparray) -> str:
return to_katex(rec_inference(self.model, self.tokenizer, [image_nparray], accelerator=self.inf_mode, num_beams=self.num_beams)[0])
class TexTellerDetServer:
def __init__(self, inf_mode='cpu'):
self.infer_config = PredictConfig("./models/det_model/model/infer_cfg.yml")
self.latex_det_model = InferenceSession("./models/det_model/model/rtdetr_r50vd_6x_coco.onnx", providers=['CUDAExecutionProvider'] if inf_mode == 'cuda' else ['CPUExecutionProvider'])
def predict(self, image_nparray) -> str:
with tempfile.TemporaryDirectory() as temp_dir:
img_path = f"{temp_dir}/temp_image.jpg"
cv2.imwrite(img_path, image_nparray)
latex_bboxes = det_inference(img_path, self.latex_det_model, self.infer_config)
return latex_bboxes
rec_server = TexTellerRecServer(CHECKPOINT_DIR, TOKENIZER_DIR, inf_mode=INFERENCE_MODE, use_onnx=USE_ONNX, num_beams=NUM_BEAMS)
det_server = None
if Path('./models/det_model/model/rtdetr_r50vd_6x_coco.onnx').exists():
det_server = TexTellerDetServer(INFERENCE_MODE)
class DetectionResponse(BaseModel):
request_type: str
result: str
elapsed_time: float
class RecognitionResponse(BaseModel):
request_type: str
result: str
elapsed_time: float
def verify_token(authorization: str = Header(...)):
if authorization != "4f3c2d1e5a6b7c8d9e0f1a2b3c4d5e6faede":
raise HTTPException(status_code=401, detail="Unauthorized")
@app.post("/formula_det", response_model=DetectionResponse, summary="检测公式位置", description="检测图像中的公式位置。")
async def detect(img: UploadFile = File(...), authorization: str = Depends(verify_token)):
"""
检测图像中的公式位置。
- **img**: 上传的图像文件
- **Authorization**: 请求头中的授权令牌
返回包含检测结果和处理时间的JSON响应。
"""
start_time = time.time()
img_rb = await img.read()
img_nparray = np.frombuffer(img_rb, np.uint8)
img_nparray = cv2.imdecode(img_nparray, cv2.IMREAD_COLOR)
img_nparray = cv2.cvtColor(img_nparray, cv2.COLOR_BGR2RGB)
if det_server is None:
raise HTTPException(status_code=404, detail="rtdetr_r50vd_6x_coco.onnx not found.")
pred = det_server.predict(img_nparray)
end_time = time.time()
elapsed_time = end_time - start_time
return JSONResponse(content={"request_type": "detection", "result": pred, "elapsed_time": elapsed_time})
@app.post("/formula_rec", response_model=RecognitionResponse, summary="识别公式", description="识别图像中的公式。")
async def recognize(img: UploadFile = File(...), authorization: str = Depends(verify_token)):
"""
识别图像中的公式。
- **img**: 上传的图像文件
- **Authorization**: 请求头中的授权令牌
返回包含识别结果和处理时间的JSON响应。
"""
start_time = time.time()
img_rb = await img.read()
img_nparray = np.frombuffer(img_rb, np.uint8)
img_nparray = cv2.imdecode(img_nparray, cv2.IMREAD_COLOR)
img_nparray = cv2.cvtColor(img_nparray, cv2.COLOR_BGR2RGB)
pred = rec_server.predict(img_nparray)
end_time = time.time()
elapsed_time = end_time - start_time
return JSONResponse(content={"request_type": "recognition", "result": pred, "elapsed_time": elapsed_time})
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang="ch",ocr_version="PP-OCRv4")
@app.post("/paddle_ocr", response_model=RecognitionResponse, summary="通用识别", description="")
async def recognize(img: UploadFile = File(...), authorization: str = Depends(verify_token)):
start_time = time.time()
img_rb = await img.read()
img_nparray = np.frombuffer(img_rb, np.uint8)
img_nparray = cv2.imdecode(img_nparray, cv2.IMREAD_COLOR)
img_nparray = cv2.cvtColor(img_nparray, cv2.COLOR_BGR2RGB)
pred = ""
result = ocr.ocr(img_nparray, cls=True,)
texts = [item[1][0] for sublist in result for item in sublist]
for line in texts:
pred = pred + line + "\n"
end_time = time.time()
elapsed_time = end_time - start_time
return JSONResponse(content={"request_type": "paddleocr", "result": pred, "elapsed_time": elapsed_time})
if __name__ == '__main__':
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=SERVER_PORT)
|